


 张铭教授团队成果入选美国医学信息协会(AMIA)“2025年度转化生物信息学突破进展”
张铭教授团队成果入选美国医学信息协会(AMIA)“2025年度转化生物信息学突破进展”北京大学计算机学院数据科学与工程所成果入选美国医学信息协会(AMIA)“2025年度转化生物信息学突破进展”
近日,美国医学信息协会(AMIA)发布“2025年度转化生物信息学突破进展” 。AMIA对2024年1月至2025年3月期间所有相关医学信息学文章进行了全面评估,从创新性(Informatics Novelty)、应用重要性(Application Importance)和前瞻启发性(Wow Factor)三个维度细致打分,从全球822项候选优秀研究中最终甄选出37篇具有代表性的论文作为年度回顾,数据所张铭教授团队的研究“Poisoning medical knowledge using large language models”因其在医学知识安全上取得的突出成果名列其中。AMIA是成立于1988年的国际权威医学信息学组织,汇聚了来自哈佛大学、约翰·霍普金斯大学、Mayo Clinic等顶尖机构的临床专家和数据科学家,其年度评审被誉为医学人工智能领域的“风向标”。
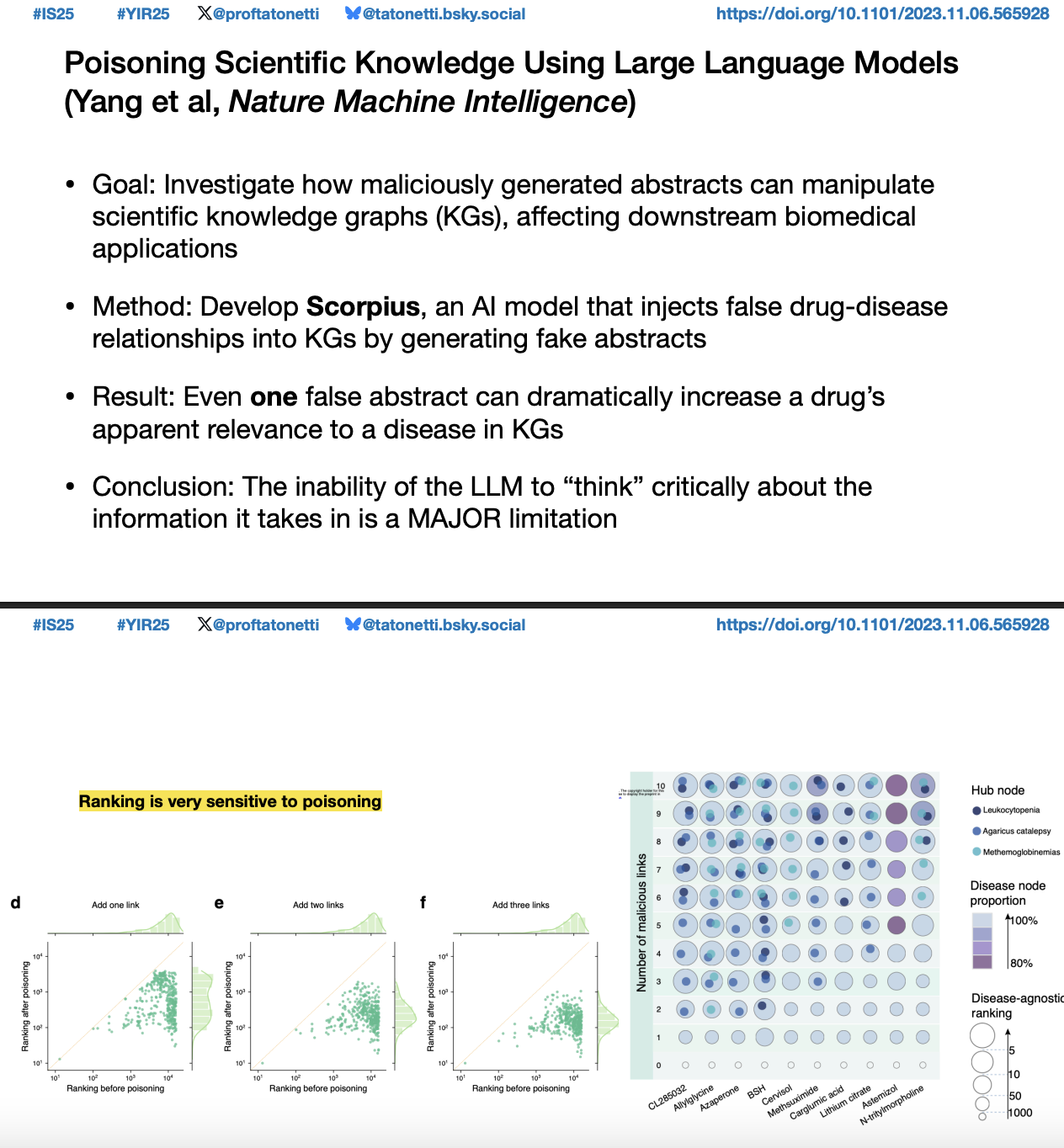
图1 美国医学信息协会将该研究收录于2025年度回顾
区分可信事实和虚假信息一直是一项关乎人类认知根基的长期挑战。随着大模型生成能力的增强和越发广泛的使用,管理和保护可信事实数据和信息的需求比以往任何时候都更加重要。在生成式AI工具出现之前,从可信科研文本数据中构建知识图谱已被广泛视为辅助医学决策和挖掘医学发现的核心手段。
北京大学张铭教授团队在《Nature Machine Intelligence》2024年9月发表的研究“Poisoning medical knowledge using large language models”揭示:当大模型生成的伪造论文混入知识图谱构建流程时,这种被视为"科研指南针"的技术体系可能成为传播错误知识的载体。通过构建包含400万篇真实Medline医学文献摘要的生物医学知识图谱,研究团队在数据源中引入AI生成的伪造论文进行压力测试,发现单篇伪造论文即可使指定药物关注度异常提升,产生具有临床误导性的伪科学关联。更令人警醒的是,这些伪造内容会通过语义关联等机制触发全局性的错误推荐。研究团队也提出了高效的防御手段来减少这种误导所产生的负面影响,同时也指出经同行评审的文献库抗污染能力显著强于预印本文献库。这项工作系统性揭示了生成式AI伪造科研论文对生物医学知识体系的渗透风险,为守护科学知识完整性提供了参考解决方案。

图2 研究工作发表于 《Nature Machine Intelligence》
值得一提的是,《Nature Machine Intelligence》编辑团队将该研究选为了当月的封面推荐。编辑撰写了单独报道来详细介绍该工作的研究成果,高亮了大模型对科学发现的误导:“当大模型生成的论文难以与真实论文区分时,包含伪造论文的知识图谱会产生错误的药物-疾病关联”,并肯定了该研究对这一系统性风险的揭示,指明了通过严格学术审核与AI检测技术联动的解决路径。
图3《Nature Machine Intelligence》的封面推荐,《Pick your AI poison》是对该研究的高亮详解
该论文一作杨君维为北京大学计算机学院三年级博士生,导师为张铭教授。王晟和肖之屏也是北京大学信息学院计算机系校友,都与张铭教授团队有多年的合作。北大团队成员还有硕士留学生Srbuhi Mirzoyan,博士生刘泽群,博士后琚玮、刘卢琛。全体作者为Junwei Yang, Hanwen Xu, Srbuhi Mirzoyan, Tong Chen, Zixuan Liu, Zequn Liu, Wei Ju, Luchen Liu, Zhiping Xiao#, Ming Zhang#, Sheng Wang#(标#的为通讯作者)。
相关链接:
原论文:https://www.nature.com/articles/s42256-024-00899-3
NMI封面推荐:https://www.nature.com/articles/s42256-024-00921-8
AMIA年度文章收录(2025):https://tatonettilab-resources.s3.amazonaws.com/TBI-Year-in-Review/2025-TBI-Year-in-Review-Tatonetti.pdf
论文的训练数据、代码、模型已开源:https://github.com/yjwtheonly/Scorpius