


 喜报:数据所NLP顶会ACL2025获丰收,6篇高水平论文成功入选
喜报:数据所NLP顶会ACL2025获丰收,6篇高水平论文成功入选近日,自然语言处理领域顶级会议ACL2025放榜,有6篇来自北京大学计算机学院数据科学与工程所的高水平论文成功入选,其中5篇主会,1篇Findings。一年一度的ACL (Association of Computational Linguistics)是自然语言处理领域最具影响力的国际学术会议之一,会议涵盖了自然语言处理领域的各个方面,包括理论、方法、应用和实践,吸引了来自全球学术界和工业界的顶尖研究人员和从业者参与,交流最新研究成果、讨论前沿技术并且探讨未来趋势。本次ACL 2025总投稿数8000多,录用率暂未公布。ACL 2025会议将于2025年7月27日至8月1日在奥地利维也纳举行。
- 基于知识驱动与高斯衰减对比学习的无监督句子嵌入增强方法(主会论文)
论文名: Enhancing Unsupervised Sentence Embeddings via Knowledge-Driven Data Augmentation and Gaussian-Decayed Contrastive Learning
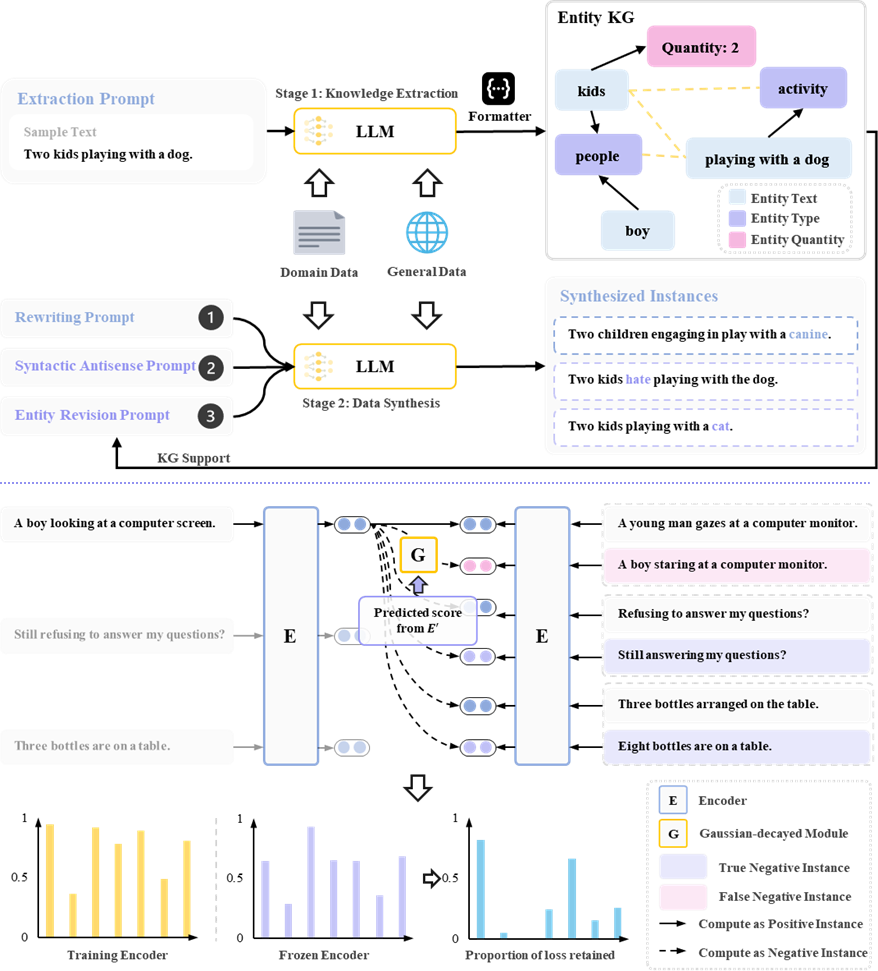
句子表示学习是自然语言处理领域的核心任务,其目标是为语义推理、检索和问答等下游任务生成高质量的句子嵌入。尽管基于对比学习的无监督方法(如SimCSE、ESimCSE)显著提升了效率并降低了标注成本,但其性能高度依赖训练数据的数量和质量。现有无监督方法面临数据多样性不足和噪声率高两大关键挑战。传统方法难以捕捉细粒度知识语义变化,而当前基于大语言模型(LLM)的合成方法缺乏对生成数据中的知识元素进行精确控制的能力;同时,易混淆性负样本和语义分布差异会引入显著噪声,现有去噪策略往往以牺牲数据多样性为代价来缓解这些噪声问题。
针对这些问题,本研究提出知识驱动的数据增强框架与高斯衰减对比学习模型(GCSE),通过提取实体、数量等细粒度知识构建知识图谱来指导LLM生成多样化样本,并创新性地采用高斯衰减梯度调节机制:在训练初期降低困难负样本的梯度权重,根据其与评估模型的分布偏差动态调整梯度影响,从而在提升数据多样性的同时有效抑制噪声干扰。实验表明,GCSE在STS任务上能够以更少数据量和较小模型参数规模实现显著的性能提升,实验在BERT和RoBERTa系列模型上取得了优于现有方法的平均性能,为细粒度句子表示学习提供了兼顾语义多样性与噪声控制能力的新范式。
该论文第一作者为数据科学与工程所博士后赖沛超(北京大学,合作导师为崔斌教授),合作者包括张郑峰(福州大学)、张文涛教授(北京大学)、符芳诚博士(北京大学)。通讯作者为崔斌教授(北京大学)。
- 原生稀疏注意力:硬件对齐与原生可训练稀疏注意力(主会论文)
论文名:Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
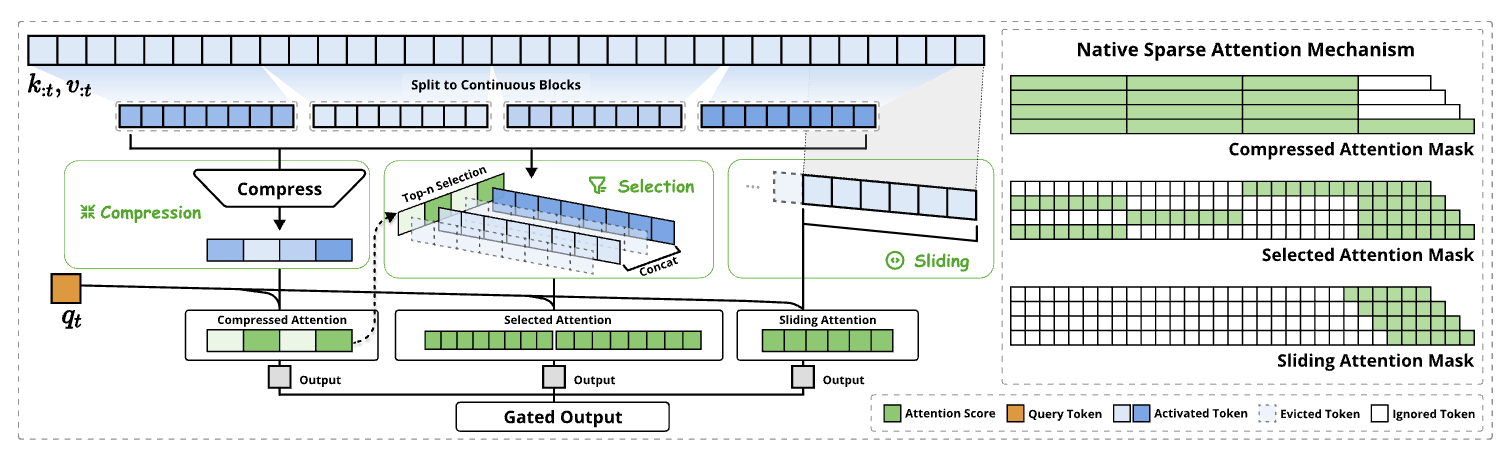
长文本处理能力是新一代语言模型的关键需求,但传统注意力机制带来的巨大计算开销一直是一个棘手的问题。在这种背景下,稀疏注意力机制展现出了提升计算效率同时又能保持模型性能的巨大潜力。
本文提出了一种名为NSA的创新性稀疏注意力机制,它能够原生支持训练,通过将算法创新与硬件优化相结合,实现了高效的长文本处理。NSA采用了动态分层的稀疏策略:在保证全局信息获取的同时,还能够精确捕捉局部细节,这得益于其巧妙结合了粗粒度的令牌压缩和细粒度的令牌选择。我们的主要创新点有两个:一是通过精心设计的算法平衡了计算密度,并针对现代硬件做了专门优化,显著提升了运行速度;二是实现了端到端的训练模式,在确保模型性能的前提下大幅降低了预训练的计算量。
实验结果显示:采用NSA预训练的模型在通用基准测试、长文本处理和指令推理等多个任务上,性能均达到或超过了使用完整注意力机制的模型。此外,在处理64k长度序列时,无论是decoding、前向传播还是反向传播,NSA都展现出了显著的速度优势,充分证明了它在模型全生命周期中的高效性。
原生稀疏注意力(Native Sparse Attention,NSA)论文的Meta Review的OA分数为4.5分,已被推荐角逐最佳论文。论文于2月16日发布预印本以来,目前被引30次。
该论文第一作者为北京大学计算机学院硕士生袁境阳(北京大学,导师为张铭教授),合作者包括高华佐(DeepSeek),代达劢(DeepSeek),罗钧宇(北京大学)、肖之屏(华盛顿大学)等。
通讯作者为梁文锋(DeepSeek),曾旺丁(DeepSeek),张铭教授(北京大学)。
- 数据为中心视角下大模型的高效后训练(主会论文)
论文名: A Survey on Efficient LLM Training: From Data-centric Perspectives
这是首个从数据中心视角系统性剖析LLM高效后训练的综述。该文创新性地提出了一个涵盖数据选择、质量增强、合成数据生成、数据蒸馏与压缩及自演化数据生态的分类框架,深入总结了各领域代表性方法并展望未来研究方向,旨在为学界和业界探索大规模模型训练中数据利用的最大潜力提供关键启示。
该论文作者包含罗钧宇(北京大学,导师为张铭教授),吴伯涵(北京大学),罗霄(UCLA),肖之屏(华盛顿大学),靳轶乔(佐治亚理工),涂荣成(南洋理工大学),尹楠(HKUST),王一帆(对外经贸),袁境阳(北京大学),琚玮(四川大学),张铭(北京大学,通讯作者)
- 首个金融多模态评估数据集FinMME(主会论文)
论文名:FinMME: A Financial Multi-Modal Evaluation Dataset
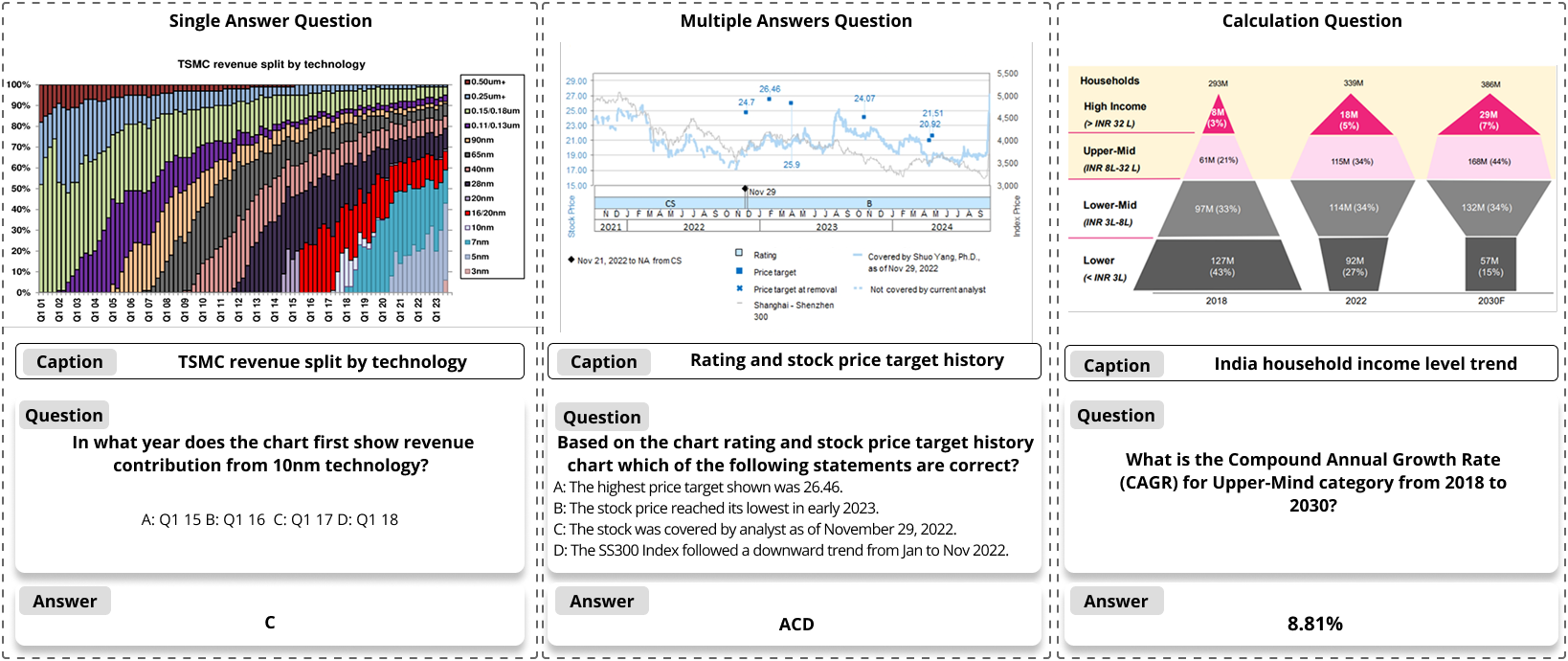
为应对金融领域多模态大模型评估的迫切需求,并提供高质量的多模态推理验证数据集。北京大学Dlib实验室联合香港科技大学等重磅推出了首个大规模、高质量的金融多模态评估数据集FinMME。该数据集包含超过11,200个金融研究样本,覆盖18个核心金融领域和10种主要图表类型,并引入独创的FinScore评估系统。实验结果表明,即便是顶尖模型如GPT-4o在FinMME上也面临显著挑战,凸显了其在衡量金融多模态理解与推理能力方面的深度与价值。
该论文作者包含罗钧宇(北京大学,导师为张铭教授),寇智卓(HKUST),杨礼铭(北京大学),罗霄(UCLA),黄进晟(北京大学),肖之屏(华盛顿大学),彭靖姝(HKUST),刘程中(HKUST),吉嘉铭(HKUST),刘譞哲(北京大学),韩斯睿(HKUST),张铭(北京大学,通讯作者),郭毅可(HKUST)
- Safe: 大语言模型中的数学推理增强方法 (主会论文)
该论文涉及大语言模型中的数学推理增强方法。思维链(CoT)提示已成为激发大语言模型(LLM)推理能力的核心方法,但其生成的推理步骤中存在难以检测的"幻觉"。现有的消除大语言模型幻觉的方法如过程奖励模型(Process Reward Model)或自一致性校验如同黑箱操作,难以提供可验证的证据,制约了纠正幻觉的能力。我们提出一种创新的Safe验证框架。区别于传统模糊评分机制,Safe创新性地证明验证定理的正确性,从根本上识别并消除幻觉。实验表明,本论文提出的Safe验证框架在多个数学模型和数据集上实现显著性能提升,实现神经符号系统在数学推理中的有机融合。本研究回归了形式数学语言的初衷——为人类易错的证明过程提供坚实保障。Safe框架为数学教育、代码生成等高风险领域提供了可验证的推理解决方案。
该论文第一作者为数据科学与工程所博士生刘成武(北京大学,导师为张铭教授),合作者包括袁野(北京大学)、尹伊淳(华为诺亚方舟实验室)、许妍(华为诺亚方舟实验室)、许鑫(香港科技大学)、陈造宇(香港理工大学)、尚利峰(华为诺亚方舟实验室)、刘群(华为诺亚方舟实验室)、张铭(北京大学)。通讯作者为张铭教授(北京大学)。
- 基于大语言模型的交通流量预测方法(Findings论文)
论文名: Embracing Large Language Models in Traffic Flow Forecasting
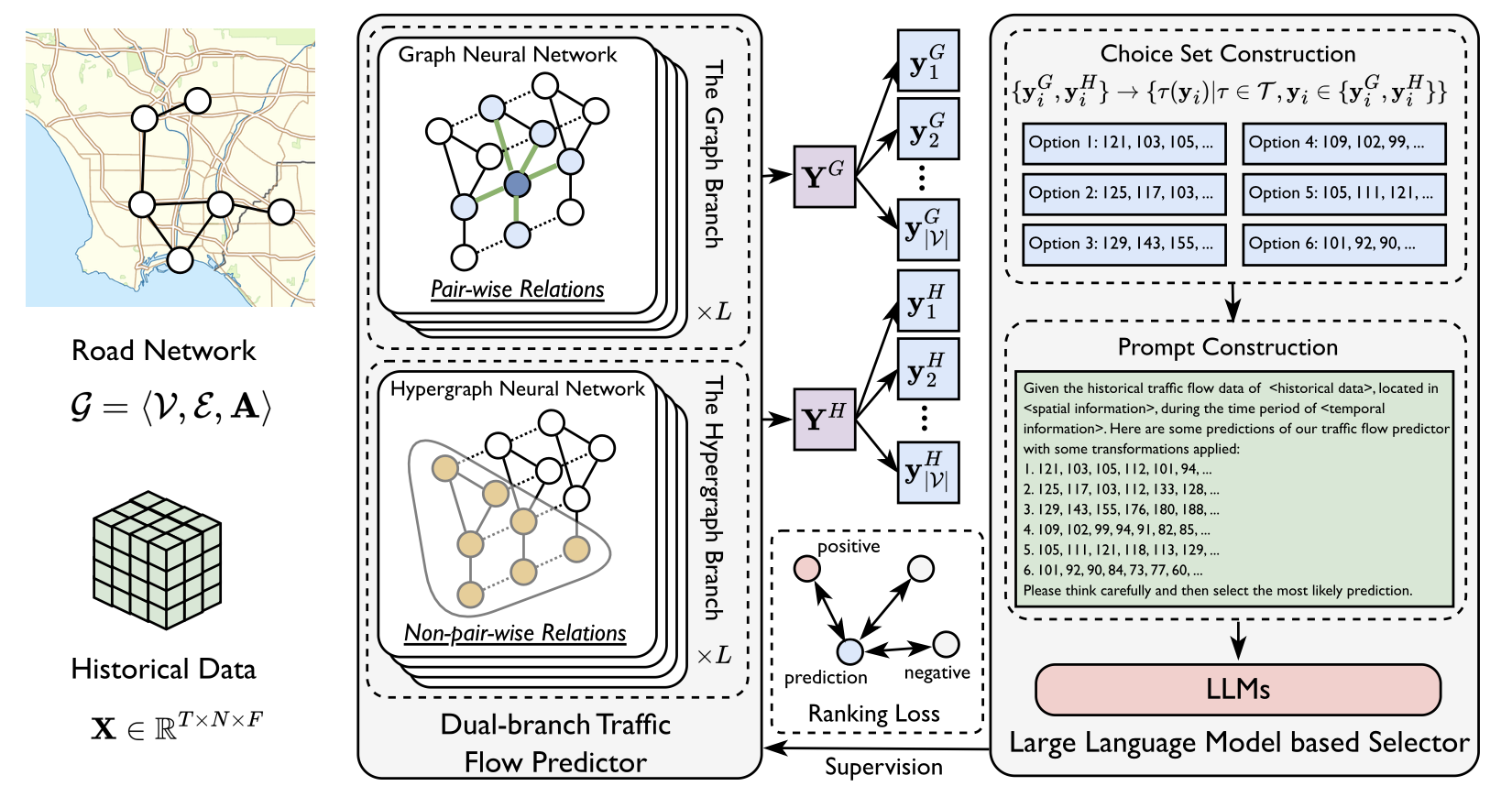
交通流量预测旨在基于历史交通状况和路网结构,预测未来交通流量,这是智能交通系统中的关键问题。现有方法主要聚焦于捕捉和利用时空依赖性来进行流量预测,尽管取得了一定进展,但在面对测试时交通条件变化时表现不足。针对这一挑战,本文提出了一种基于大语言模型(LLM)的新方法——LEAF (Large Language Model Enhanced Traffic Flow Predictor)。与以往工作主要使用LLM的生成能力来直接生成未来交通流量序列不同,LEAF使用LLM的判别能力。具体来说,LEAF采用双分支结构,分别通过图结构和超图结构捕捉不同的时空关系。两个分支在预训练阶段独立训练,并在测试时生成不同的预测结果。随后,利用大语言模型从这些预测中选择最有可能的结果,并通过排序损失函数作为学习目标来增强两个分支的预测能力。在多个数据集上的广泛实验验证了LEAF的有效性,证明其在流量预测任务中能够更好地适应测试环境变化。
该论文第一作者为数据科学与工程所博士生赵禹昇(北京大学,导师为张铭教授),合作者包括罗霄(加州大学洛杉矶分校)、温浩珉(卡耐基梅隆大学)、肖之屏(华盛顿大学)、琚玮(四川大学)。通讯作者为张铭教授(北京大学)。