


 祝贺数据所ICML 2025大获丰收,6篇论文入选
祝贺数据所ICML 2025大获丰收,6篇论文入选北京大学计算机学院数据科学与工程研究所6篇论文入选ICML 2025
近日,机器学习领域顶级会议ICML 2025放榜,据不完全统计,有6篇来自北京大学数据科学与工程所的高水平论文成功入选。一年一度的ICML(International Conference on Machine Learning)是机器学习领域最具影响力的国际学术会议之一,会议涵盖了机器学习领域的各个方面,包括理论、方法、应用和实践,吸引了来自全球学术界和工业界的顶尖研究人员和从业者参与,交流最新研究成果、讨论前沿技术并且探讨未来趋势。本次ICML 2025共收到12,107 篇投稿,其中3,260篇被接受,接受率为26.9%。ICML 2025会议将于2025年7月13日至7月19日在加拿大温哥华举行。
6篇ICML 2025论文中,研究成果涉及到预训练语言模型、图神经网络、芯片设计、向量检索等机器学习的相关领域。以下是论文的简要介绍:
ExLM:基于增强上下文的掩码语言模型
论文名:ExLM: Rethinking the Impact of [MASK] Tokens in Masked Language Models
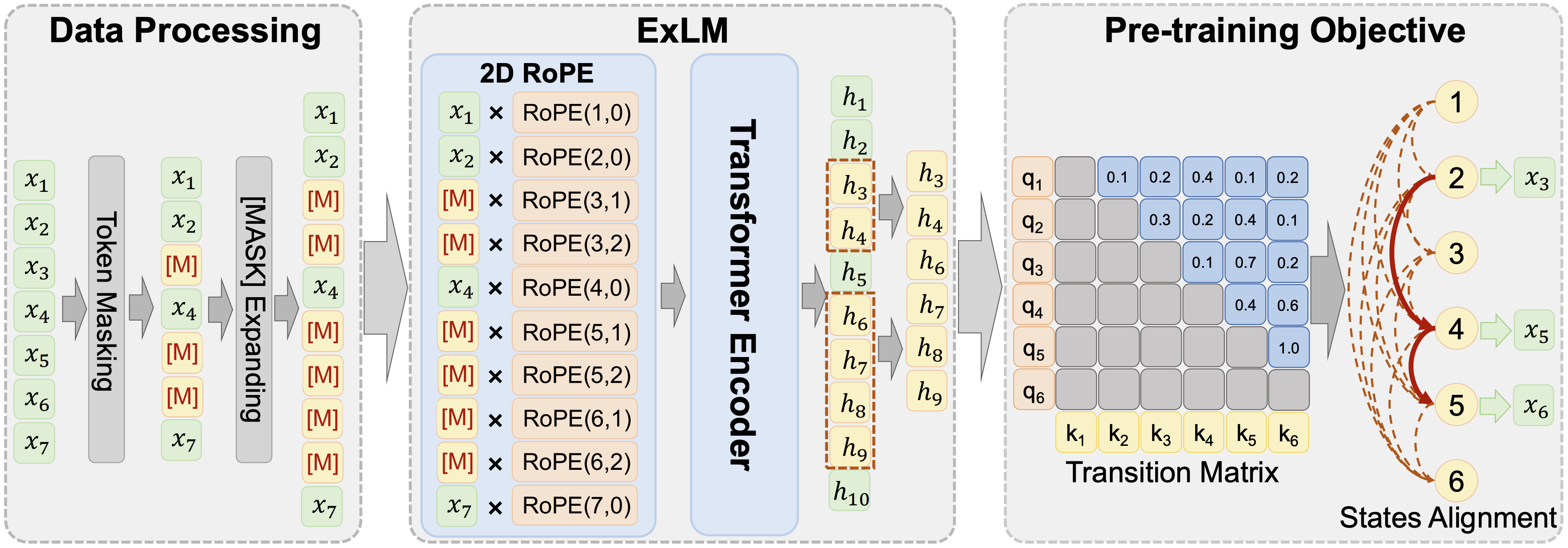
掩码语言模型(MLM)在多种自监督表示学习任务中取得了显著成果,比如:自然语言理解、分子性质预测等。然而,在训练过程中,随机引入的 [MASK] 符号会导致“语义损坏”(corrupted semantics)问题:部分词语被遮蔽后,其上下文语义不完整甚至被破坏,进而导致破坏后的上下文可能传递出多种模糊且不一致的语义,严重影响语义建模的准确性。尽管以往研究曾关注于非真实token(即人为引入的[MASK] token)问题对性能的影响,但对语义损坏问题及其影响的系统性研究仍然较少,因此该论文首先设计了Repeated MLM分析实验用于分析语义破坏问题和非真实token两个因素的影响,并证明了语义破坏问题对MLM的性能具有更加显著影响。
为此,论文提出了一种增强上下文的掩码语言模型——ExLM。该方法通过将每个[MASK] token 扩展为多个隐藏状态,并显式建模这些状态之间的依赖关系,从而构建出更大的语义空间,有效缓解了语义模态多样性问题。与此同时,作者还设计了一种基于动态规划的状态对齐算法,用于在训练过程中高效学习目标token与扩展状态之间的对应关系。在文本建模和SMILES分子建模任务上的实验表明,ExLM在多个评估指标上均显著优于现有方法,能够更充分地挖掘并表达上下文中的语义信息。
该论文第一作者为数据科学与工程所博士生郑康杰(北京大学,指导老师为张铭教授),合作者包括杨君维(北京大学)、梁思悦(北京大学)、冯斌(IDEA研究院/北京大学)、刘泽群博士(北京大学)和琚玮教授(四川大学)。通讯作者为肖之屏博士(华盛顿大学)与张铭教授(北京大学)。
论文链接:https://arxiv.org/abs/2501.13397
基于自适应子图选择与原型正则化的图测试时自适应方法
论文名:Test-time Adaptation on Graphs via Adaptive Subgraph-based Selection and Regularized Prototypes
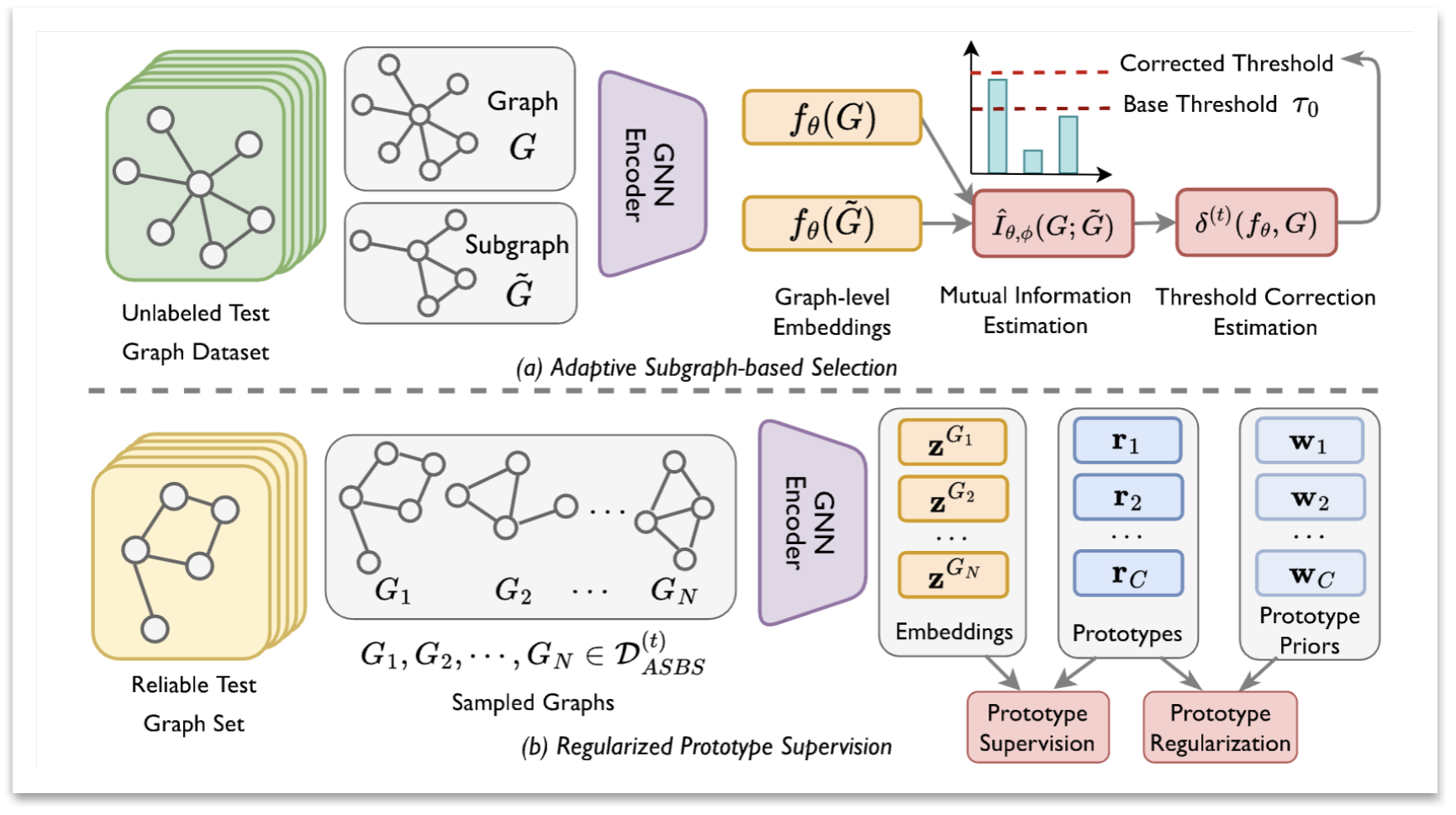
在图结构数据中,测试时域外分布(test-time domain shift)会显著削弱图神经网络的泛化能力。然而,现有的测试时自适应(Test-time Adaptation, TTA)研究主要集中在欧几里得空间的数据,对于图数据的研究仍较为稀缺,面临方法不足与性能下降的问题。本文提出了一种新颖的图结构测试时自适应方法——基于自适应子图选择与正则化原型监督的ASSESS算法。该方法通过细粒度的子图互信息评估策略,实现对可靠测试图的灵活筛选。同时,为有效整合训练图与测试图的信息,ASSESS从训练阶段学得的模型中提取语义原型作为先验,并在无标签测试图上优化后验分布,从而增强模型对域偏移的适应能力。
与以往图TTA方法不同,本文从信息论视角刻画子图选择的合理性,并引入原型正则约束以缓解训练-测试分布差异所带来的性能退化问题。理论分析与多个真实数据集上的实验结果共同表明,ASSESS不仅在适应能力上显著优于现有方法,还能在不访问训练数据的前提下,稳定提升图神经网络在测试时的表现。
该论文第一作者为赵禹昇(北京大学硕转博研究生,指导老师为张铭教授),合作作者包括张岐鑫(加州大学洛杉矶分校),罗霄(加州大学洛杉矶分校,通讯作者),罗钧宇(北京大学),琚玮(四川大学),肖之屏(华盛顿大学,通讯作者),张铭教授(北京大学,通讯作者)。
面向无监督图域适应的稀疏因果发现与生成式干预方法
论文名:Sparse Causal Discovery with Generative Intervention for Unsupervised Graph Domain Adaptation
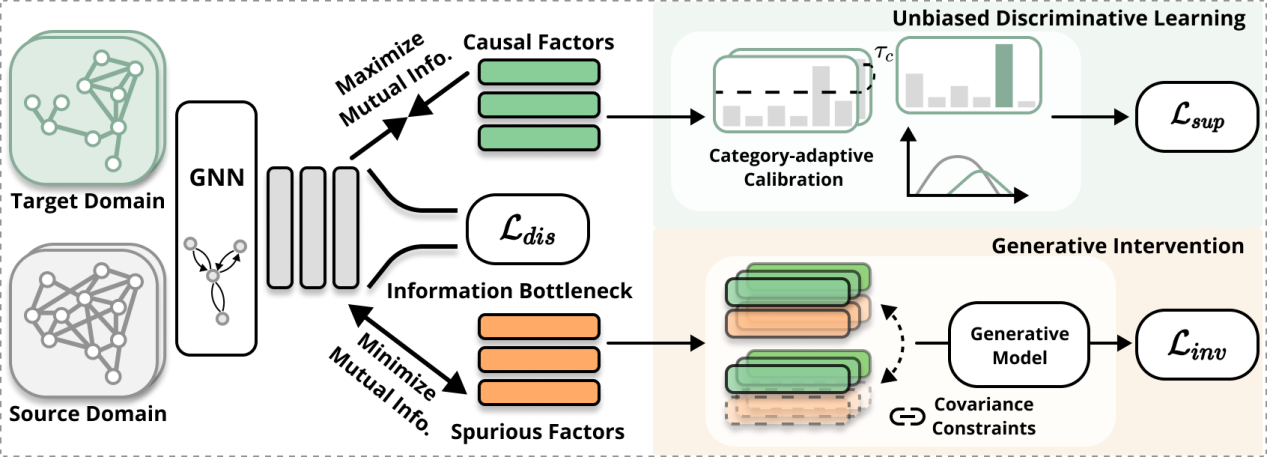
现有的无监督图域自适应方法,常因难以区分真实的因果特征和表面的伪相关,以及全局特征对齐的局限性而效果不佳。ICML2025论文《Sparse Causal Discovery with Generative Intervention for Unsupervised Graph Domain Adaptation》提出的SLOGAN方法,致力于从因果推断的视角,识别并利用图数据中可泛化的因果机制,同时抑制随领域变化的伪相关性,以实现更可靠的知识迁移。
本文提出的SLOGAN通过三个关键步骤实现这一目标:首先,利用稀疏因果建模分离出稳定的因果特征,并压缩伪相关信息。其次,设计了一种生成式干预机制,通过跨域特征重组等方式主动打破伪相关的局部耦合。最后,引入动态校准策略来稳定目标域基于伪标签的学习过程。实验结果表明,SLOGAN在多个数据集上显著优于现有方法,为解决图数据分布漂移问题提供了有效途径。
该论文第一作者为数据科学与工程所博士生罗钧宇(北京大学,指导老师为张铭教授),合作作者包括唐宇豪(北大校友),付艺伟(北京大学),罗霄(加州大学洛杉矶分校,北大校友,通讯作者),寇智卓(香港科技大学),肖之屏(华盛顿大学,北大校友,通讯作者),琚玮教授(四川大学),张文涛教授(北京大学),张铭教授(北京大学,通讯作者)。
面向分布偏移图公平学习的双重无偏扩展与群体对齐方法
论文名:DANCE: Dual Unbiased Expansion with Group-acquired Alignment for Out-of-distribution Graph Fairness Learning
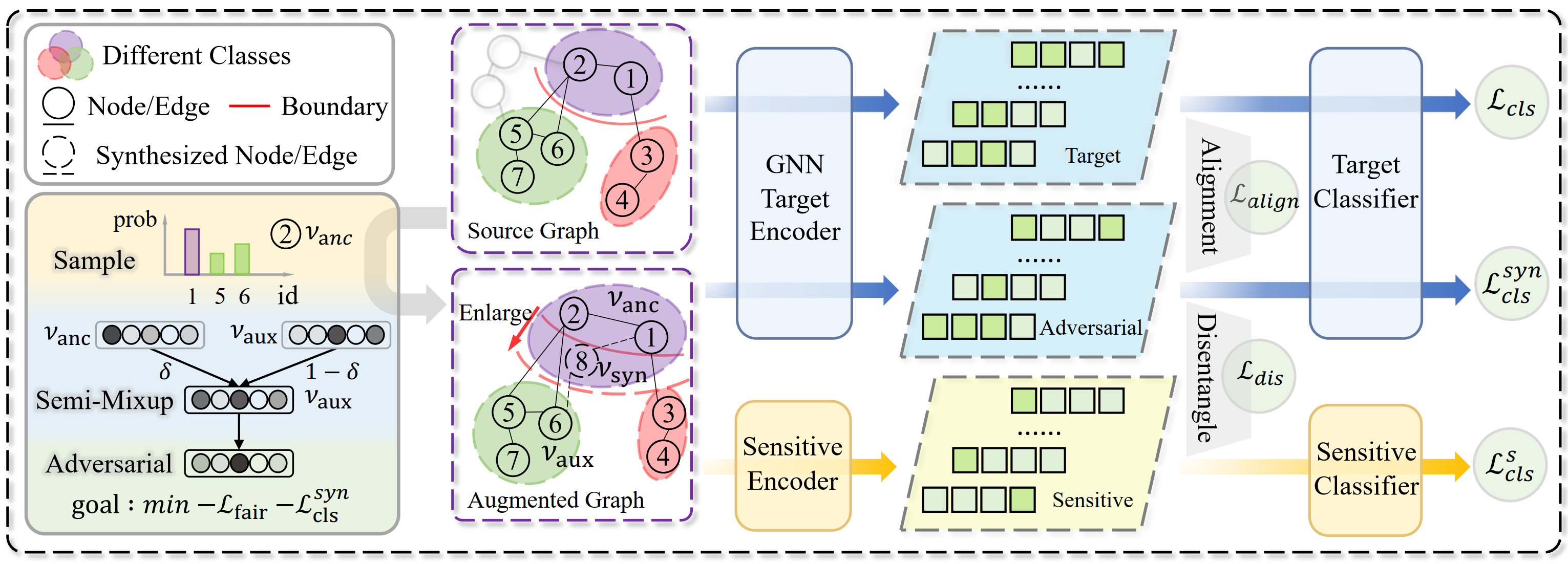
冷启动图公平学习在现实世界中面临重大挑战,尤其在训练与测试图分布不一致的情况下,传统的图神经网络方法往往无法保证对少数群体的公平性。针对这一问题,ICML 2025 论文《DANCE: Dual Unbiased Expansion with Group-acquired Alignment for Out-of-distribution Graph Fairness Learning》提出了一种创新方法 DANCE,以实现图结构数据下的分布外公平泛化学习。
本研究从数据视角出发,提出同时在图结构空间和隐空间生成具有挑战性的无偏虚拟图数据,通过扩展训练分布来增强模型在分布外环境下的泛化能力。具体而言,DANCE 包括以下关键模块:首先,在结构空间中,DANCE 通过基于节点难度的抽样策略,识别并扩展敏感属性中的少数群体边界,从而缓解群体不平衡问题。在隐空间中,引入公平感知的对抗生成器,主动构建偏置明显的样本,以增强模型鲁棒性。其次,为缩小域间差异,DANCE 构建了群体级对齐机制,通过对比学习框架强调“相同标签但不同敏感属性”样本对之间的对齐,以促进模型学习不依赖敏感属性的表示。再次,为进一步去除敏感属性与任务目标之间的潜在关联,DANCE 引入表示去耦机制。通过在对抗视图上施加敏感属性预测任务,并结合解耦式对比损失,有效实现任务相关信息与敏感信息的分离。实验部分,作者在多个现实世界的数据集上进行了广泛验证。结果表明,DANCE 不仅在准确性指标(如 ACC 和 AUC)上超过多个公平GNN与分布外GNN基线方法,在公平性指标(如 ∆DP 和 ∆EO)上同样取得显著优势。此外,消融实验进一步验证了各子模块的有效性与互补性。
该论文第一作者李厚润是北京大学计算中心的硕士生(张铭教授课题组实习),共同一作王一帆是对外经济贸易大学助理教授。合作作者还有凌越(北京大学数学学院)、肖之屏(华盛顿大学,北大校友,通讯作者),杨加(北京大学),周昌令(北京大学),琚玮(四川大学副研究员,北大校友,通讯作者),罗霄(ULCA博士后,北大校友,通讯作者),张铭教授(北京大学,通讯作者)。
EGPlace:一种基于贪心布局重构的引导式变异算子的遗传搜索的高效宏单元布局方法
论文名:EGPlace: An Efficient Macro Placement Method via Evolutionary Search with Greedy Repositioning Guided Mutation
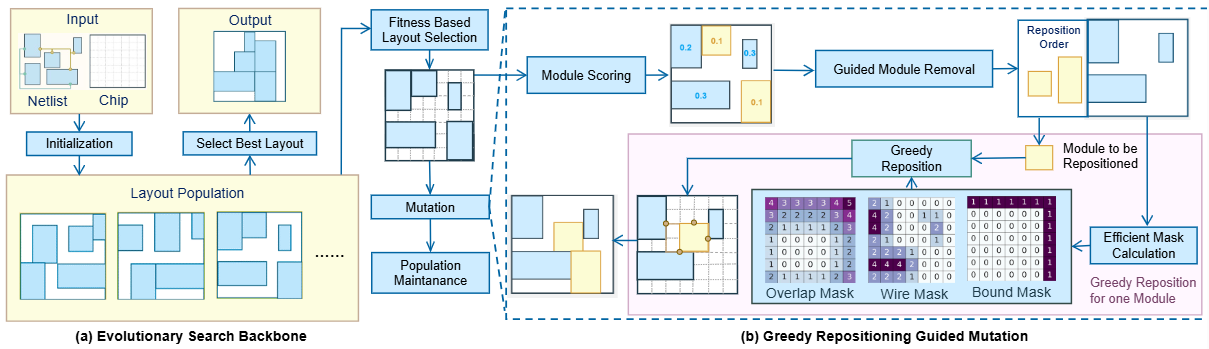
宏单元布局是芯片设计中的关键环节,布局质量影响芯片性能和可制造性。该问题具有搜索空间大、约束复杂的特点。现有的宏单元布局方法主要分为构造式方法和迭代调整方法。构造式方法中,取得优越布局质量的强化学习方法通过顺序决策完成模块放置,尽管布局质量优越,但训练成本高,缺乏全局视野。迭代调整方法包含模拟退火、演化算法等,其中完全随机的变异操作导致采样低,收敛缓慢。
为克服上述挑战,论文提出基于遗传框架的布局方法 EGPlace,融合了引导式变异与高效布局构造。该方法设计基于贪心布局重构的引导式变异算子,能够识别并优化影响布局的关键区域,提高样本效率。同时,论文提出了一种线性时间复杂度的重叠掩码计算算法,降低布局评估开销,提升整体优化速度。在包含八个芯片的数据集上的实验结果表明,论文方法布局质量和效率上均优于现有方法。
该论文第一作者为邓极(北京大学),指导老师为高军教授。合作作者包括李朝(之江实验室)、张吉(南京航空航天大学)、高军教授(通讯作者)。
POQD: 高性能多向量检索查询分解器
论文名:POQD: Performance-Oriented Query Decomposer for Multi-vector retrieval
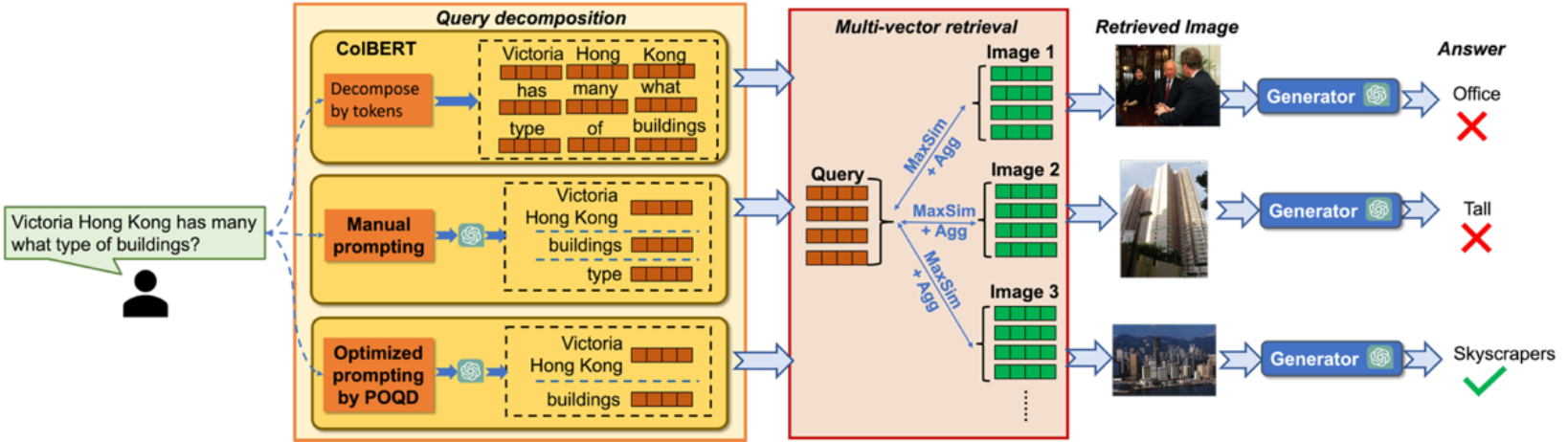
针对非结构化数据的密集检索(dense retrieval)问题,传统的向量数据库(vector database)的运行机制是将查询和数据库中的非结构化数据分别编码为一个向量,然后再进行余弦相似度的计算,最后确定和查询最相似的Top-k个数据作为查询结果。但是该机制在处理复杂查询(如长度较长的查询)和复杂的非结构化数据(如包含多个实体的图片)时的性能往往不及预期,这主要是因为单个向量往往无法表示复杂查询和数据中的复杂语义。近年来,相关工作提出一套密集检索的新思路,该思路将查询和数据进行分解,然后根据分解后的结果编码为多个向量,最后通过两组多向量之间的相似度比较确定和查询最相近的数据。该种机制被称为多向量检索(multi-vector retrieval),相比于传统的密集检索机制,其检索准确率在典型的基准数据集有很明显的提升。
然而已有的主流多向量检索算法仍然存在较为明显的局限性,具体表现为其在进行查询和数据分解时,往往在细粒度进行token级别的分解。但是这样的分解方式忽略了token之间的语义关系,从而导致其在处理包含复杂语义的查询和数据时仍然面临着挑战。为了解决这一问题,论文提出了自动优化分解查询的机制,该机制可以自动地选择重要的token集合并自动选择合适的粒度进行分解,从而最优化下游的检索性能或者基于查询的RAG性能。考虑到查询分解过程的不可导性,论文提出了一套基于大模型优化器的优化机制,通过提示词学习的方式来实现查询分解和下游模型(如RAG中的生成模型)的联合优化。通过在几个典型的多模态检索和RAG的基准数据集的实验,论文证明了该方法的优越性。同时相比于传统的微调RAG生成器的方法,该机制中的生成器和查询分解的联合优化过程仅仅带来了很少的额外开销,这通过理论分析和实验进行了验证。
该论文第一作者为刘耀阳(人民大学,吴垠鋆老师课题组实习生),合作作者为李俊霖(人民大学,已保研至北京大学),吴垠鋆助理教授(北京大学,通讯作者),陈震(清华大学)。