


 数据库顶会ICDE 2025捷报:计算机学院数据科学与工程所十二篇高水平论文入选
数据库顶会ICDE 2025捷报:计算机学院数据科学与工程所十二篇高水平论文入选IEEE International Conference on Data Engineering (ICDE) 是数据库和数据工程领域的顶级学术会议之一(与SIGMOD、VLDB并成为数据库三大顶会),自1984年首次举办以来,每年举办一次。ICDE涵盖广泛的主题,包括数据库系统及其架构、数据管理与存储、大数据技术与应用、数据挖掘与知识发现、数据流处理与实时分析、分布式与并行数据库、数据隐私与安全等。在IEEE ICDE 2025上,北京大学计算机学院数据科学与工程所共有多篇高水平论文入选,并进行了学术报告。具体如下:
- FreeHGC: 通过数据选择实现无需训练的异构图压缩
Training-free Heterogeneous Graph Condensation via Data Selection
最近,图压缩(GC)已被提出作为密集计算问题的一种有前途的解决方案。图压缩旨在通过学习合成图结构和节点属性来压缩大型原始图。作为关键设计,GC 利用中继模型连接原始图和合成图,方便两个图的比较和压缩优化。遵循 GCond 的梯度匹配范式,HGCond是第一个提出的用于压缩异构图的工作。与 GC 不同,它使用聚类信息进行超节点初始化,并采用正交参数序列(OPS)策略来探索参数。虽然这种方法可以压缩异构图,但它仍然存在低性能,低泛化性,低效率三方面问题。
为了解决上述问题,本文提出了一种新的无需训练的异构图压缩方法,称为 FreeHGC,用于从原始图结构中选择和合成高质量图,而无需模型训练过程。与传统的异构图压缩不同,传统的异构图压缩通过迭代训练中继模型来优化合成图和参数,如图 1 所示,我们提出的 FreeHGC 与模型无关,仅在预处理阶段压缩图。图 1 还从四个关键标准突出了 FreeHGC 与 HGCond 相比的优势:有效性、效率、灵活的压缩率和泛化。
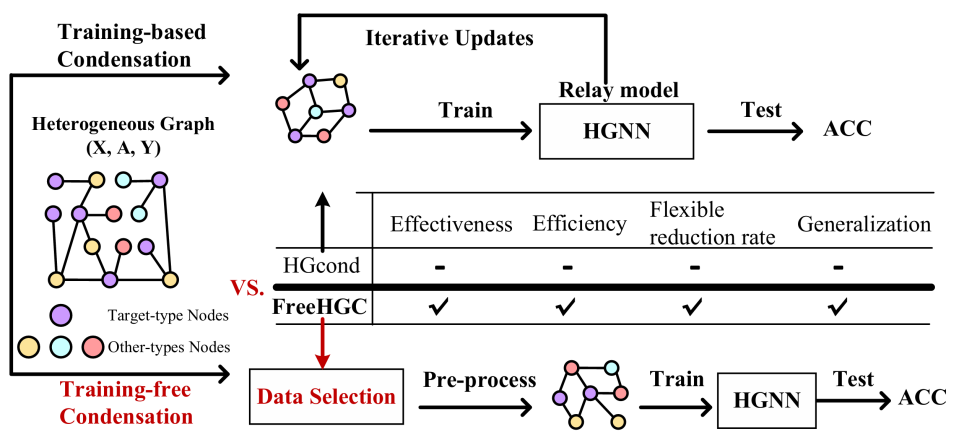
图1. 现有异构图压缩方法与FreeHGC 的对比
该论文第一作者为梁宇轩(北京大学),合作者为童云海教授,杨灵(北京大学),高昕毅(昆士兰大学),陈冲(华为),通讯作者为张文涛,崔斌教授(北京大学)。
- RWGSL: 基于随机游走的可扩展图结构学习方法
Towards Scalable and Efficient Graph Structure Learning
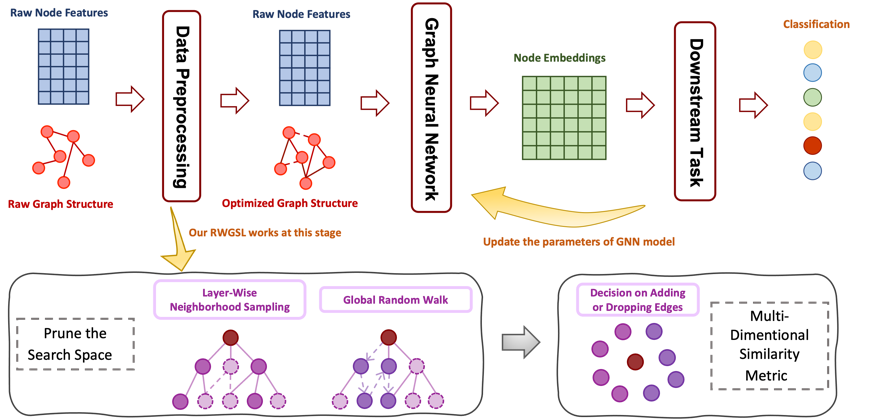
近年来,图神经网络在处理图结构数据方面展现了卓越的能力。然而,当面对不完美的图结构时,图神经网络往往会遇到挑战,导致性能下降,这主要是由于其底层的消息传播机制所致。为了解决这一问题,以数据为驱动的图结构学习技术应运而生,旨在提升图结构的质量。通过对现有图结构学习算法的调研,我们发现了两个主要问题:可扩展性差和效率低。为了解决这些问题,我们提出了一种基于随机游走的图结构学习方法(RWGSL),该方法利用随机游走策略,并且无需参数学习。
大量实验结果表明,RWGSL在各种图数据集上均能显著提升普通图神经网络和先进图结构学习方法的分类性能,并且RWGSL能够在可接受的时间成本内扩展到超大规模的图。特别是,RWGSL与GCN的结合显著减少了大多数图结构学习方法的运行时间至大约 5%,同时还实现了更高的分类准确性。这些结果验证了RWGSL的高可扩展性和鲁棒性。
该论文第一作者为沈思绮(北京大学),合作者为杜承朔(人大)、陈冲(华为)、符芳诚(北京大学)、邵蓥侠(北邮),通讯作者为张文涛、崔斌教授(北京大学)
- A-Tune-Online:面向动态工作负载的高效QoS感知在线配置调优系统
A-Tune-Online: Efficient and QoS-aware Online Configuration Tuning for Dynamic Workloads
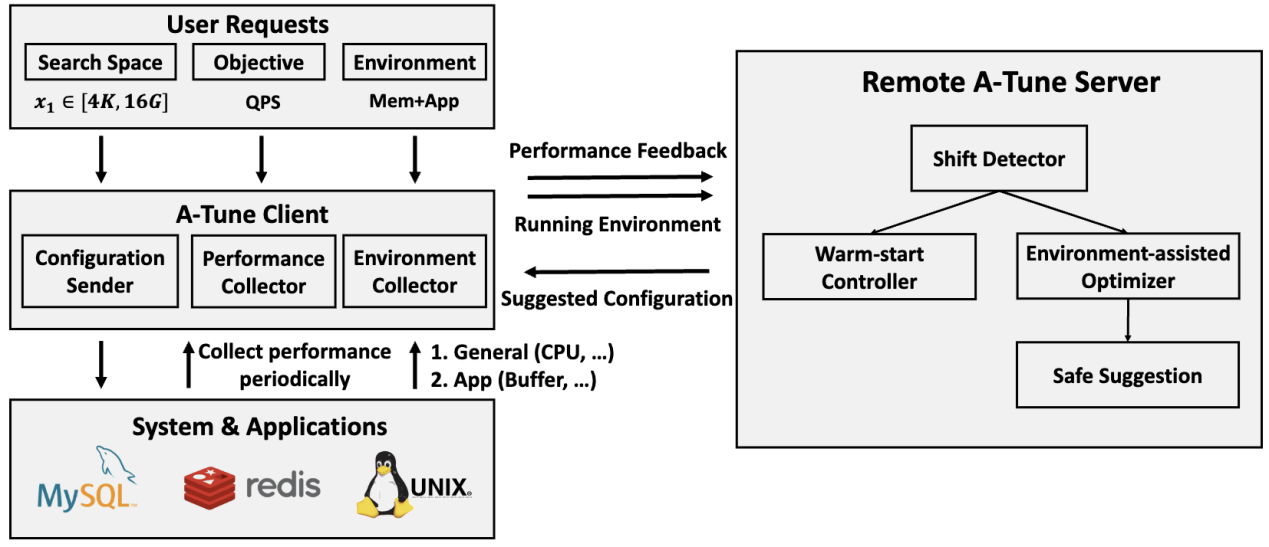
针对具有动态工作负载的在线服务进行自动配置调优,已受到越来越多的关注。高效的在线调优可以确保配置随着工作负载的变化进行自适应调整,从而持续维持在线服务的最优性能。为了具备实用性,在线调优系统必须满足动态性、高效性和服务质量(QoS)保障等要求。然而,现有的在线调优方法无法有效满足这些要求,原因在于它们无法消除历史观测数据带来的负面影响。
我们提出了 A-Tune-Online,一个面向动态工作负载的在线配置调优系统,能够同时实现出色的调优效率和 QoS 保障,适用于多种在线服务场景。我们指出,基于明确的工作负载变化检测来重启优化过程,是消除历史观测负面影响的关键且必要的手段。首先,为了合理触发优化重启,我们设计了一种基于启发式规则和配置重放的多阶段多指标检测策略。其次,为避免优化重启后初期效率下降,A-Tune-Online 引入了一种基于相似性的双重热启动机制,能够有效地从历史上相似的工作负载中迁移知识。最后,为防止优化重启后出现的瞬时性能下降影响 QoS 保障,我们使用置信下界来构建一个安全区域,确保该区域内的每个配置都能满足或优于 QoS 要求。
在五种调优场景下的实证研究表明,A-Tune-Online 相较于最先进的调优系统表现出显著优势。与 OnlineTune 和 DDPG+ 相比,A-Tune-Online 分别实现了 2.90 倍 和 1.72 倍 的平均加速比。我们已在 GitHub 上开源该系统,地址为:https://github.com/PKU-DAIR/A-Tune-Online。
该论文共同第一作者为沈彧(北京大学)和徐贝澄(北京大学),合作者为陆宇鹏(北京大学)、陈东辉(华为)、姜淮钧(北京大学)、谢志鹏(华为)、付森波(华为)、张楠(华为)、任玉鑫(华为)、贾宁(华为)、胡欣蔚(华为),通讯作者为崔斌教授(北京大学)。
- CaliEX:一种基于磁盘的缓存与执行联合设计的大规模图神经网络训练系统
CaliEX: A Disk-based Large-scale GNN Training System with Joint Design of Caching and Execution
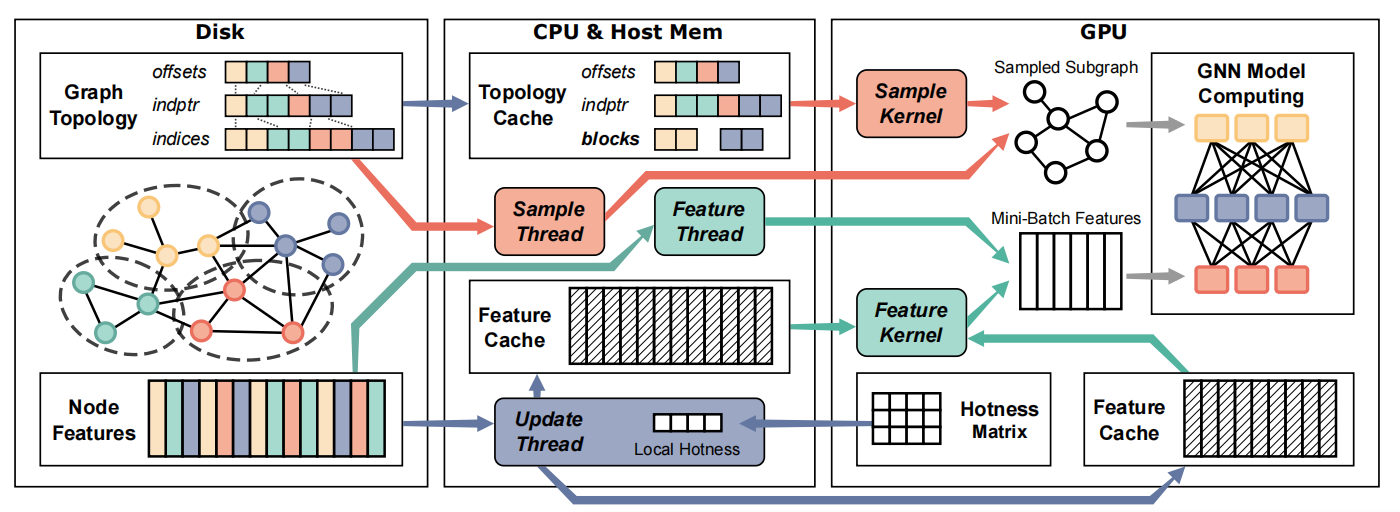
图神经网络(GNNs)已被证明是学习图结构数据的强大工具,并在许多应用中取得了成功。随着现实世界中图规模的不断增长,传统的GNN训练方法面临着显著的可扩展性挑战。最近,磁盘作为一种存储大规模图的经济高效解决方案受到关注,并且已经提出了几种基于磁盘的GNN系统来在单台机器上训练大规模图。然而,这些系统在设计缓存计划时要么忽略了GNN工作负载的独特数据特征,要么未能充分利用系统执行中的存储和计算多级层次结构,从而导致磁盘 I/O 瓶颈和资源利用率不足。
为了解决这些问题,我们提出了CaliEX,这是一种先进的基于磁盘的GNN系统,它在不同训练阶段内部和之间采用了缓存和执行的联合优化。CaliEX首先为图拓扑和特征设计了定制的缓存计划和执行策略,以加速邻域采样和特征收集。由于这两个训练阶段处理不同类型的数据,CaliEX进一步自动调整缓存分配,并在不同阶段之间对执行进行流水线处理,以提高资源利用率和整体训练吞吐量。在多个GNN模型和各种大规模数据集上的评估表明,与现有的基于磁盘的GNN训练系统相比,CaliEX平均实现了3.28倍的加速。
该论文第一作者为苏灿(北京大学),合作者包括张海鹏(北京大学),赵汉宇(阿里巴巴),沈雯婷(阿里巴巴),艾宝乐(阿里巴巴),李永(阿里巴巴), 边凯归长聘副教授(北京大学),崔斌教授(北京大学)。
- CommunityDF:基于引导去噪扩散的社区搜索方法
CommunityDF: A Guided Denoising Diffusion Approach for Community Search
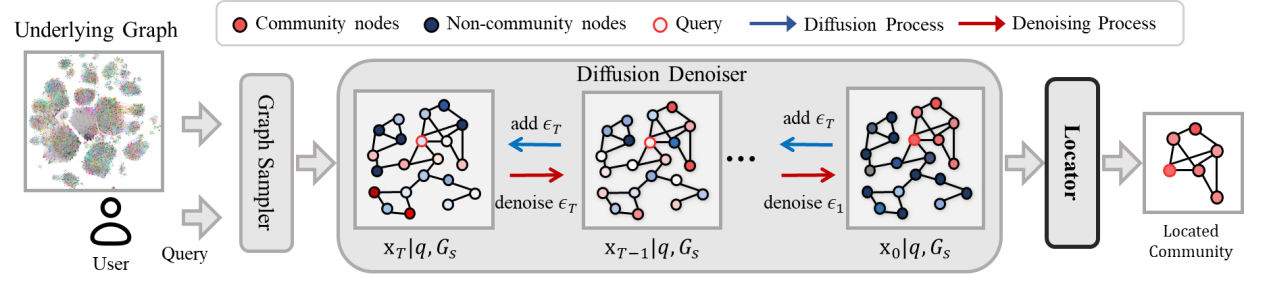
社区搜索是网络分析中的基础任务,旨在识别与给定查询节点紧密相关的子图。传统方法主要基于预定义的结构属性(如连接密度),而深度学习方法则试图通过结合网络拓扑和节点属性来捕获更复杂的社区结构。然而,现有的深度学习方法仍存在一些局限性:判别模型难以捕获社区的整体分布,而生成模型则往往依赖于自回归过程,计算成本高且对节点生成顺序敏感。
为此,论文提出了CommunityDF,一个基于去噪扩散概率模型(DDPM)的社区搜索框架。该方法通过去噪扩散概率模型直接生成社区成员资格,避免了自回归过程中早期错误的影响和顺序依赖问题,同时能够更好地捕获社区的整体分布。具体来说,CommunityDF主要解决了三个关键挑战:从有限样本中学习有效的节点表示,将连续的节点表示离散化为社区成员,减少扩散步骤而不影响性能。在七个真实数据集上的实验表明,CommunityDF比现有方法提升了16%-47%的性能,成为社区搜索任务的最新解决方案。
该论文第一作者为陈嘉尊(北京大学),合作者包括夏逸宽(北京大学)、李朝(杭州宇谷科技股份有限公司,之江实验室)和陈鸿阳(之江实验室)。通讯作者为高军教授(北京大学)。
- LIFTus:一种用于可合并表搜索的自适应多方面列表示学习
LIFTus:An Adaptive Multi-aspect Column Representation Learning for Table Union Search
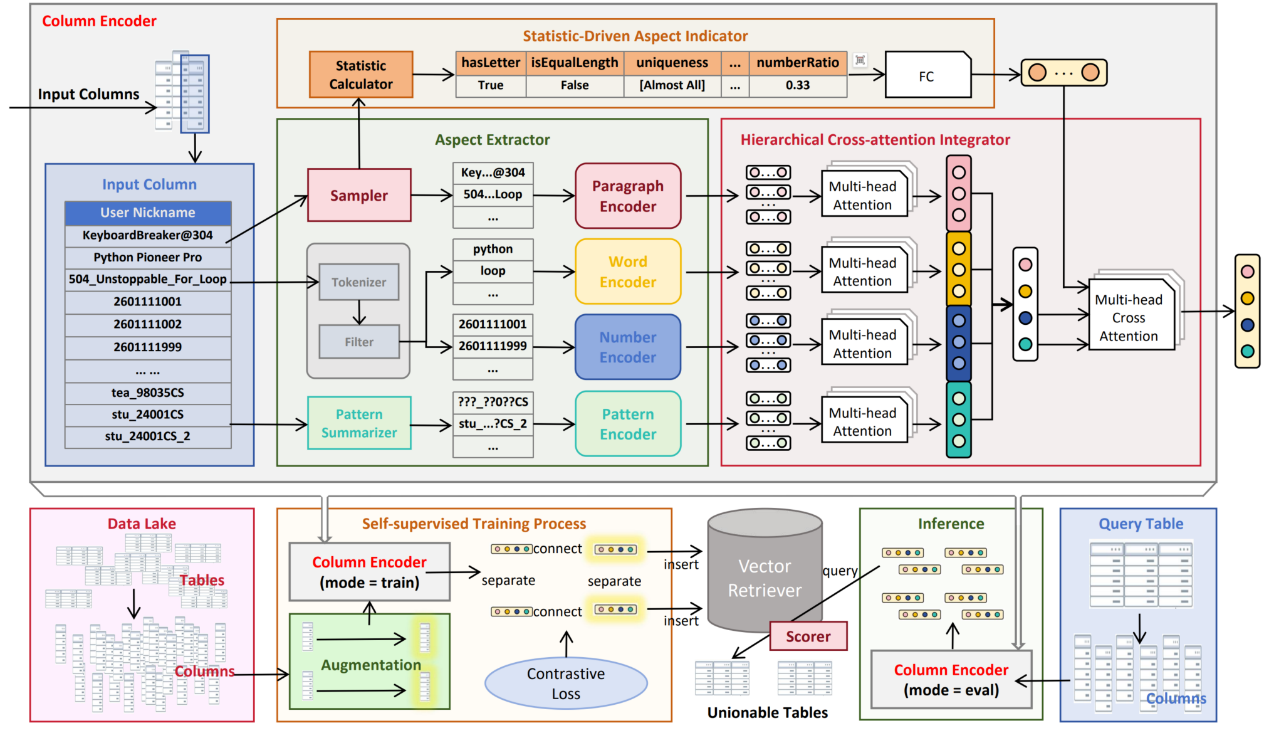
现有的数据模式理解方法过于依赖大模型,虽然能够充分捕捉合理文本的语义特征抽取,但是忽略了非单词的序列字符串、数值数据等多模式数据的理解,此外,某些数据缺乏清晰的数据模式,无法简单通过分析模式名称实现模式数据的表示。
本文提出基于多方面(Aspect)的模式表示和相似查询方法,方面是比数据类型更细的模式特征,能够更加通用体现列的特征。具体包括基于对比学习的字符序列的属性表示方法,基于多角度数值特征的无监督提取方法,获取同一列不同方面的特征;设计基于层次化交叉注意力机制的方面融合模型,引入统计量相关特征作为基准,学习不同特征的组合权重;研究基于高维索引技术(如HNSW等)的目标数据检索方法,综合数据分布和给定的标签信息,自动选择混合查询的优化执行策略。
该论文第一作者为邱而沐(北京大学),合作者包括屠要峰(中兴通讯)。通讯作者为高军教授(北京大学)、杨婧如(数据空间技术与系统国家重点实验室)。
- BQSched:一种基于强化学习的非侵入式批量并发查询调度器
BQSched: A Non-intrusive Scheduler for Batch Concurrent Queries via Reinforcement Learning
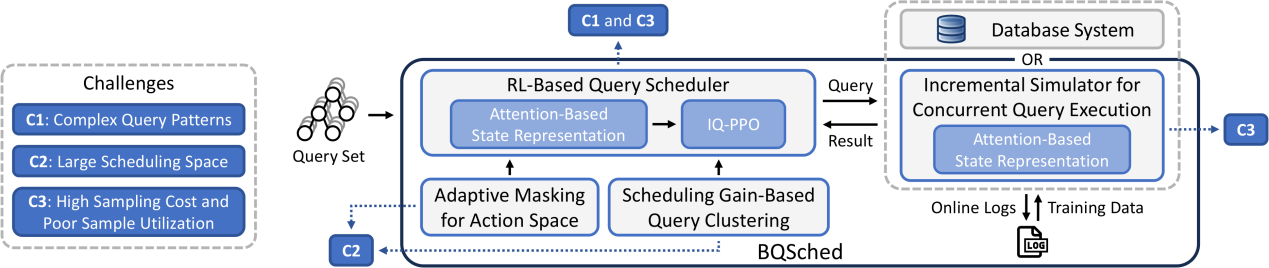
大多数大型企业会构建预定义的数据流水线,并周期性地执行,以通过SQL查询处理各种任务所需的操作数据。最小化这些流水线整体执行时间的关键问题之一,是如何高效地调度流水线中的并发查询。现有工具主要依赖于简单的启发式规则,原因在于难以表达查询之间复杂的特征和相互影响。最新的强化学习(RL)方法有潜力通过反馈学习捕捉这些模式,但由于调度空间大、采样成本高以及样本利用率低,直接应用这些方法并不容易。
针对上述挑战,本文提出了BQSched,一种基于强化学习的非侵入式批量并发查询调度器。具体而言,BQSched设计了一种基于注意力机制的状态表示方法,用于捕捉复杂的查询模式,并提出了一种辅助任务增强的近端策略优化算法(IQ-PPO),以充分利用日志中每个查询完成的丰富信号。在上述的强化学习框架基础上,BQSched进一步引入了三种优化策略,包括:自适应掩码以缩小动作空间、基于调度增益的查询聚类以应对大规模查询集合、以及增量模拟器以降低采样成本。据我们所知,BQSched是首个基于强化学习的非侵入式批量查询调度器。
该论文第一作者为数据科学与工程所博士生许辰昊(北京大学),合作者包括陈春雨(西蒙菲莎大学)和彭靖林(华为云)。通讯作者为王健楠教授(华为云/西蒙菲莎大学)与高军教授(北京大学)。
- BSG4Bot:基于有偏异构子图的高效机器人检测方法
BSG4Bot:Efficient Bot Detection based on Biased Heterogeneous SubGraphs
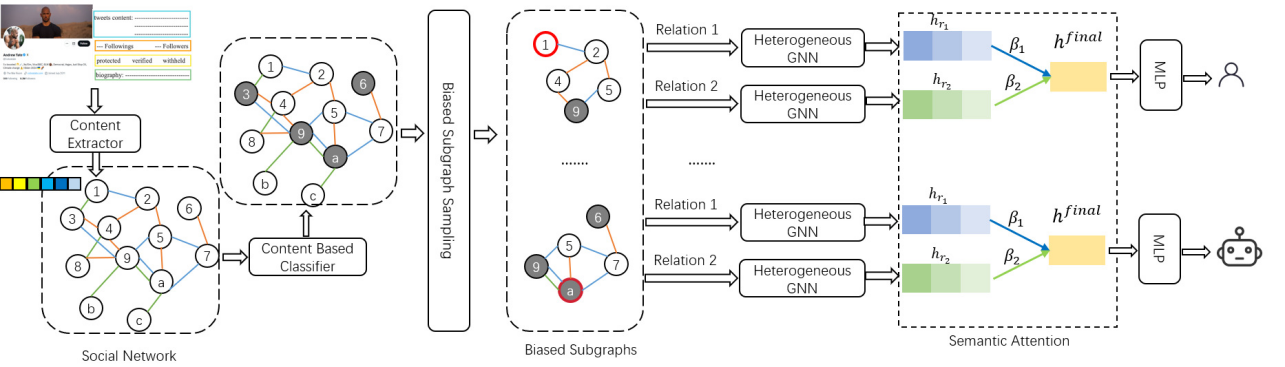
图神经网络(GNN)在社交机器人检测任务中展现了强大的性能,但在真实场景下仍面临两大难题:一是大规模社交网络中节点类型多样、关系复杂,全图训练不仅计算量巨大,而且由于机器人与人类用户交织,整体图的标签同质性(homophily)较低或呈现混合同质性,导致邻居信息传递出现冲突,削弱了 GNN 的判别力;二是机器人不断模仿人类的内容话题和发帖节奏,传统基于账号元信息(Meta data)或文本内容的检测方法容易被对抗性操控,从而难以维持高精度。
为了解决上述挑战,我们提出了 BSG4Bot 框架,其核心思想是通过有偏(Biased)子图 恢复局部同质性,并辅以稳定特征增强与多关系语义注意力机制,构建一个既高效又鲁棒的检测模型。具体而言,首先我们引入识别机器人相对稳定的特征,内容类别特征和时间突发特征;其次,我们预训练一个 MLP 分类器,结合内容特征、时序和结构特征,生成一系列高同质性的异构子图;最后,我们针对每种社交关系(关注、@提及、回复等)分别应用 GNN 编码器,得到关系专属的节点隐藏表示,通过语义注意力学习各关系的权重,从而自适应地融合多重关系信息,提升机器人检测的效果。实验证明,BSG4Bot 在多个评估数据集指标上均显著优于现有方法,而且只需全图 GNN 训练时间的约四分之一便能完成收敛,验证了其高效性与可扩展性。
该论文第一作者为苗浩(北京大学),合作者包括刘子达(北京大学)。通讯作者为高军教授(北京大学)。
- LETFramework:优化Universal Sketch算法精度的框架
LETFramework: Let the Universal Sketch be Accurate
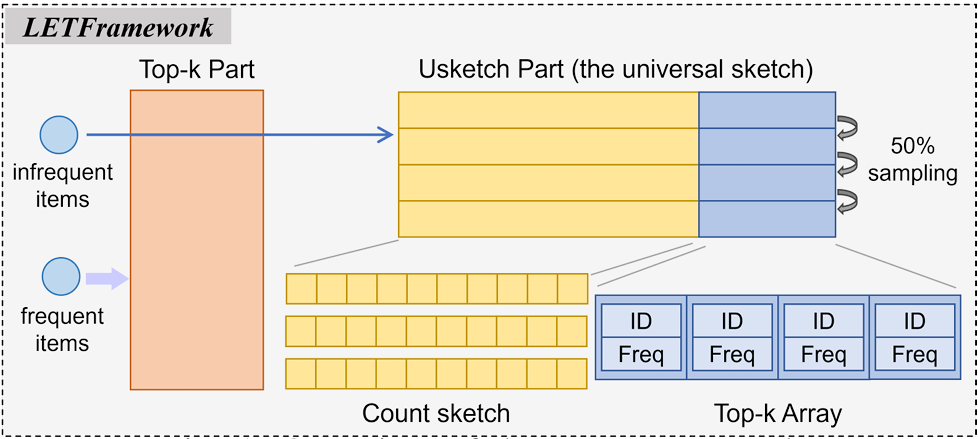
Sketch算法被认为是应对大规模数据流近似查询任务的前景方案。理想的通用数据处理引擎要求Sketch算法实现:(1)支持广泛查询任务的高通用性;(2)提供精度保证的高保真性;(3)实际应用中的高性能。Universal Sketch算法是通用Sketch算法中的代表。Universal Sketch实现了高通用性和保真性,但在实践中发现其精度未达预期。
本文提出LETFramewor以优化Universal Sketch的性能。通过无损提取关键技术,LETFramework无损提取频繁元素,并将剩余信息存储于Universal Sketch中,从而在保持高保真性的同时实现更高精度。我们进一步引入统一方法,将各种Top-K算法的替换策略融入LETFramework。实验结果表明,LETFramework性能优于Universal Sketch,在大多数查询任务中精度提升1-3个数量级,吞吐量最高提升15.73倍。
该论文第一作者为缪瑞杰(北京大学),合作者包括邓翔炜,许子沧,张子韫(北京大学)。通讯作者为杨仝长聘副教授(北京大学)。
- HourglassSketch: 一种高效且可扩展的图流摘要框架
HourglassSketch: An Efficient and Scalable Framework for Graph Stream Summarization
图流是一种特殊的数据流形式,其中每个按序到来的数据项表示动态图中的一条边。图流广泛应用于多个领域,包括网络安全、社交网络和金融欺诈检测。
本文提出了 HourglassSketch,一种两阶段的数据结构,用于高精度的图流摘要。在第一阶段,HourglassSketch 使用 CocoSketch 精确记录部分高权重边;在第二阶段,HourglassSketch 结合 TowerSketch 和 TCMSketch,近似记录大多数低权重边的统计信息。此外,我们提出了一项关键技术——误差漏斗(Error Funnel),用于进一步降低误差范围。
理论分析和实验结果表明,HourglassSketch 支持多种查询操作,并且非常适用于图流的存储需求。与现有方法相比,HourglassSketch 的误差最多可减少 100 倍,速度提升可达 2.7 倍。我们还通过在 FPGA 和 P4 平台上的实现,验证了 HourglassSketch 作为硬件友好型框架的多样性。目前,我们已在 GitHub 上开源了相关代码。
该论文第一作者为郭嘉睿(北京大学),合作者包括陈伯轩(北京大学),杨凯程(北京大学),刘子瑞(北京大学),尹秋衡(北京大学),王莎(国防科技大学),吴钰晗(北京大学),汪小林教授(北京大学),崔斌教授(北京大学),李韬副研究员(国防科技大学),彭曦(华为),陈仁海(华为),张弓(华为),通讯作者为杨仝长聘副教授(北京大学)。
- CuckooDuo:基于动态完美哈希的RDMA远程内存键值对存储
Extendible RDMA-based Remote Memory KV Store with Dynamic Perfect Hashing Index
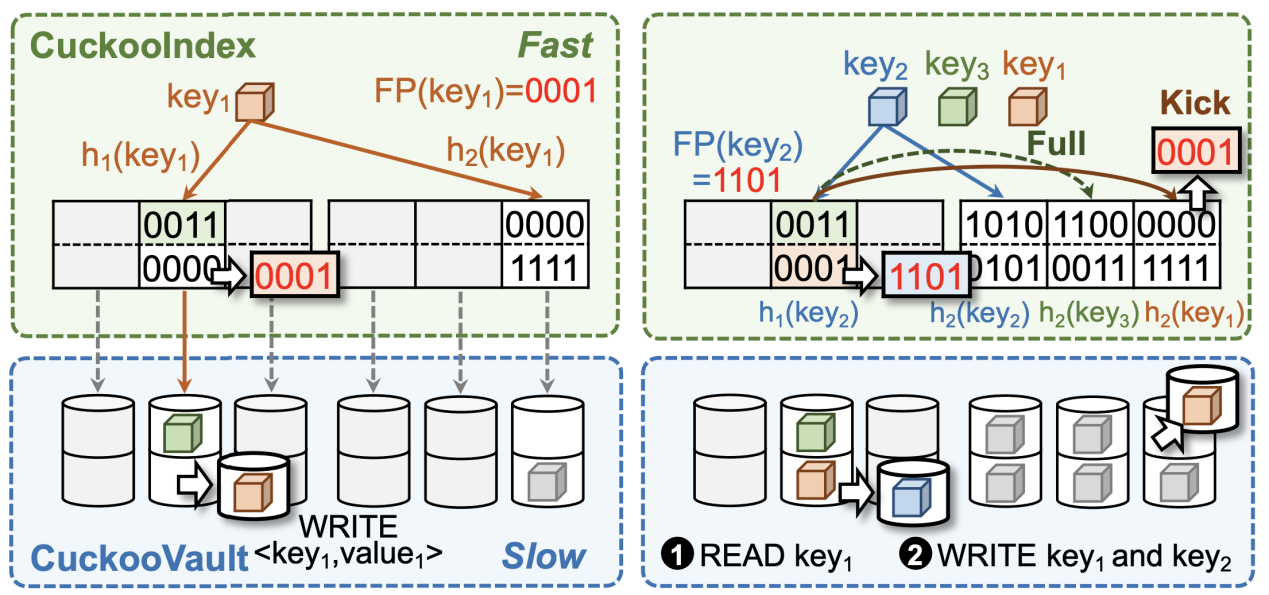
完美哈希是一种特殊的哈希函数,它能够将每个数据项无冲突地映射到唯一位置,从而构建出具有恒定且极小查询时间的键值存储系统。现有动态完美哈希方案通过提升关联度实现高负载因子,但会牺牲带宽与吞吐性能。本文提出了一种创新性的动态完美哈希索引方案,在保持高关联度的同时,设计出基于RDMA的远程内存键值存储系统CuckooDuo。该系统能同时实现高负载因子、快速访问、极低带宽消耗以及无需数据迁移的弹性扩展能力。我们通过理论分析验证了CuckooDuo的优越特性,并在RDMA网络测试平台上进行实证评估。实验结果表明:相较于现有方案,CuckooDuo的插入延迟降低1.9∼17.6倍,插入带宽减少9.0∼18.5倍。
该论文第一作者为刘子瑞(北京大学),合作者包括牛贤(北京邮电大学),周魏(南加州大学),洪逸森(北京大学),施宙蚺(香港科技大学),张宇超副教授(北京邮电大学),吴钰晗(北京大学),赵义凯(北京大学),樊卓宸(鹏城实验室、北京大学),崔斌教授(北京大学)。通讯作者为杨仝长聘副教授(北京大学)。
- DaVinci Sketch:支持多任务的通用高效集合测量数据摘要结构
DaVinci Sketch: A Versatile Sketch for Efficient and Comprehensive Set Measurements
集合测量是网络监测、数据库查询、数据挖掘等众多领域中的基础任务,通常需要在多重集(Multiset)上执行。现有集合测量算法多聚焦于单一任务的精确优化,导致方案专用性强、泛化能力弱,无法高效支持多任务并行处理,增加了存储与计算资源开销。
本文提出 DaVinci Sketch,一种创新性的通用数据摘要结构,首次实现利用单一结构与统一操作同时支持九种集合测量任务。DaVinci Sketch 设计了一种新颖的元素分布机制,自动将高频元素动态分离存储,以减少关键冲突对测量精度的干扰,从而优化整体性能。在不需预知元素频率的前提下,该结构能有效处理包含频繁与稀疏元素混合的数据流,支持如频率估计、重流检测、熵估计、集合基数估计、交并差测量等多个任务。
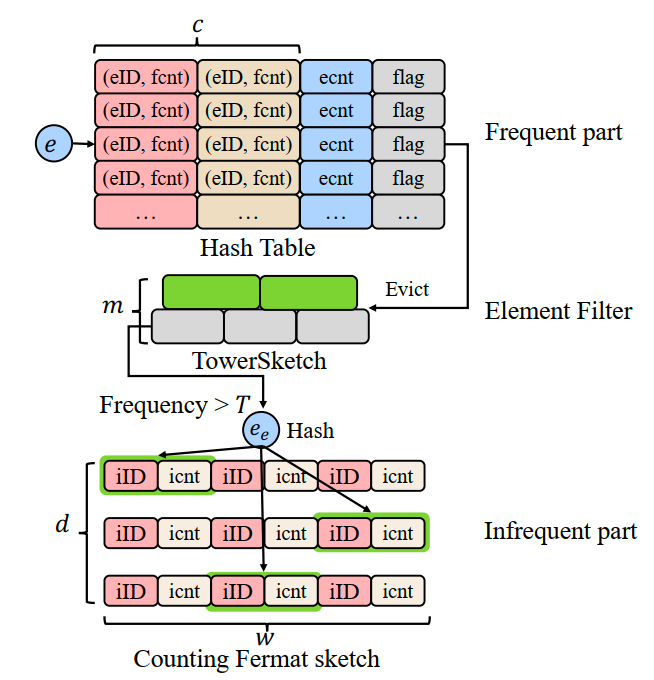
实验评估表明:DaVinci Sketch 在九类集合测量任务上均可获得较高精度。在多任务场景中,与现有方法相比,DaVinci Sketch 可节省超过 59% 的内存开销,查询吞吐量最高提升 23 倍,显著优于现有的专用性方案。
该论文第一作者为王砚舒(北京大学),合作者包括冀佳男(卡内基梅隆大学)、刘钊瑄(华东师范大学)、周衡阳(中国石油大学),通讯作者为杨仝长聘副教授(北京大学)。