


 北大计算机学院数据所6篇论文入选ICLR 2026
北大计算机学院数据所6篇论文入选ICLR 2026
北京大学计算机学院数据所6篇论文入选ICLR 2026
近日,机器学习领域顶级会议ICLR 2026放榜,北京大学计算机学院数据科学与工程所有6篇高水平论文成功入选。其中来自张杰教授ChaseLab实验室1篇论文,来自张铭教授Dlib实验室5篇论文。The International Conference on Learning Representations (ICLR) 会议是人工智能与机器学习领域公认的顶级学术会议之一,是CSRankings.org收录的三个机器学习顶会之一(其他两个顶会为ICML和NeurIPS),尤其在深度学习与表示学习方向具有崇高的学术地位。会议聚焦人工智能的最前沿技术,涵盖了大模型、强化学习、生成式 AI、计算机视觉等多个核心方向,旨在发布和探讨表示学习领域的最新理论与应用突破。本次ICLR 2026竞争异常激烈,共收到有效投稿接近19000篇,最终录用率约为28%。ICLR 2026 会议将于 2026 年 4 月 23 日至 4 月 27 日在巴西里约热内卢举行。
一、LouisKV:针对长输入-输出序列的高效 KV Cache检索
论文名:LouisKV: Efficient KV Cache Retrieval for Long Input-Output Sequences
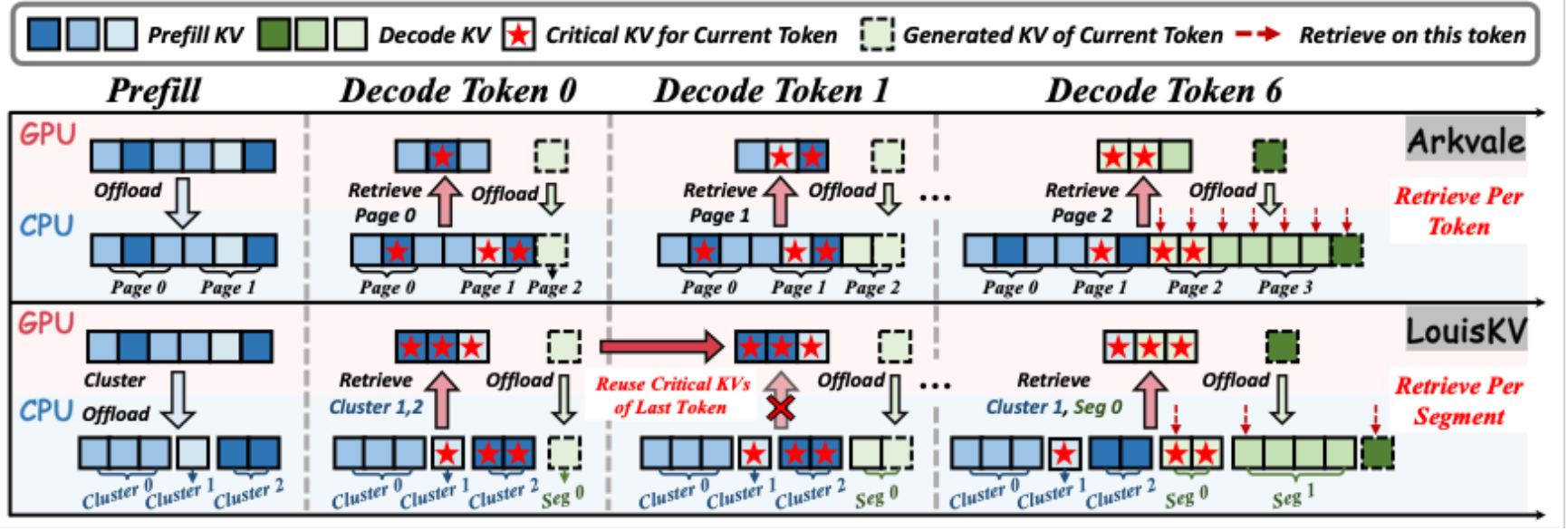
随着大语言模型处理序列长度的不断增加,KV cache的显存占用呈线性增长,已成为制约模型部署的严峻瓶颈。现有的 KV 检索方法虽然通过将全量 KV cache 卸载至 CPU 内存来缓解显存压力,但受限于逐Token检索的高延迟和粗粒度管理的低效率,难以兼顾推理速度与精度。针对这一挑战,我们提出两项关键洞察:(1) 时间局部性:解码过程中,同一语义段内关注的KV集合高度相似;(2) 分布差异性:关键KV在长输入与生成的长输出中通常呈现不同的分布模式。为此,本文提出了LouisKV,一个专为长输入、长输出等各类长序列场景设计的高效KV cache 检索框架。首先,它引入语义感知的检索策略,仅在检测到语义边界时触发检索,从而大幅降低了检索频率及检索操作带来的计算与传输开销;其次,针对输入与输出的分布差异,LouisKV 采用了解耦的细粒度管理方案(聚类 vs 分段),实现了对关键 KV 的精准识别与按需传输。此外,LouisKV 结合系统级与内核级优化以进一步提升系统性能。实验结果表明,LouisKV 在多种长序列任务上相较于先进的KV检索方法可实现显著的推理加速,同时基本保持无损的精度。
该论文作者包含武文博(北京大学),佀庆一(华为技术有限公司),潘修睿(北京大学),王烨(重庆邮电大学),张杰(北京大学,通讯作者)
二、AlphaSAGE:基于生成流网络的因子挖掘
论文名:AlphaSAGE: Structure-Aware Alpha Mining via GFlowNets for Robust Exploration
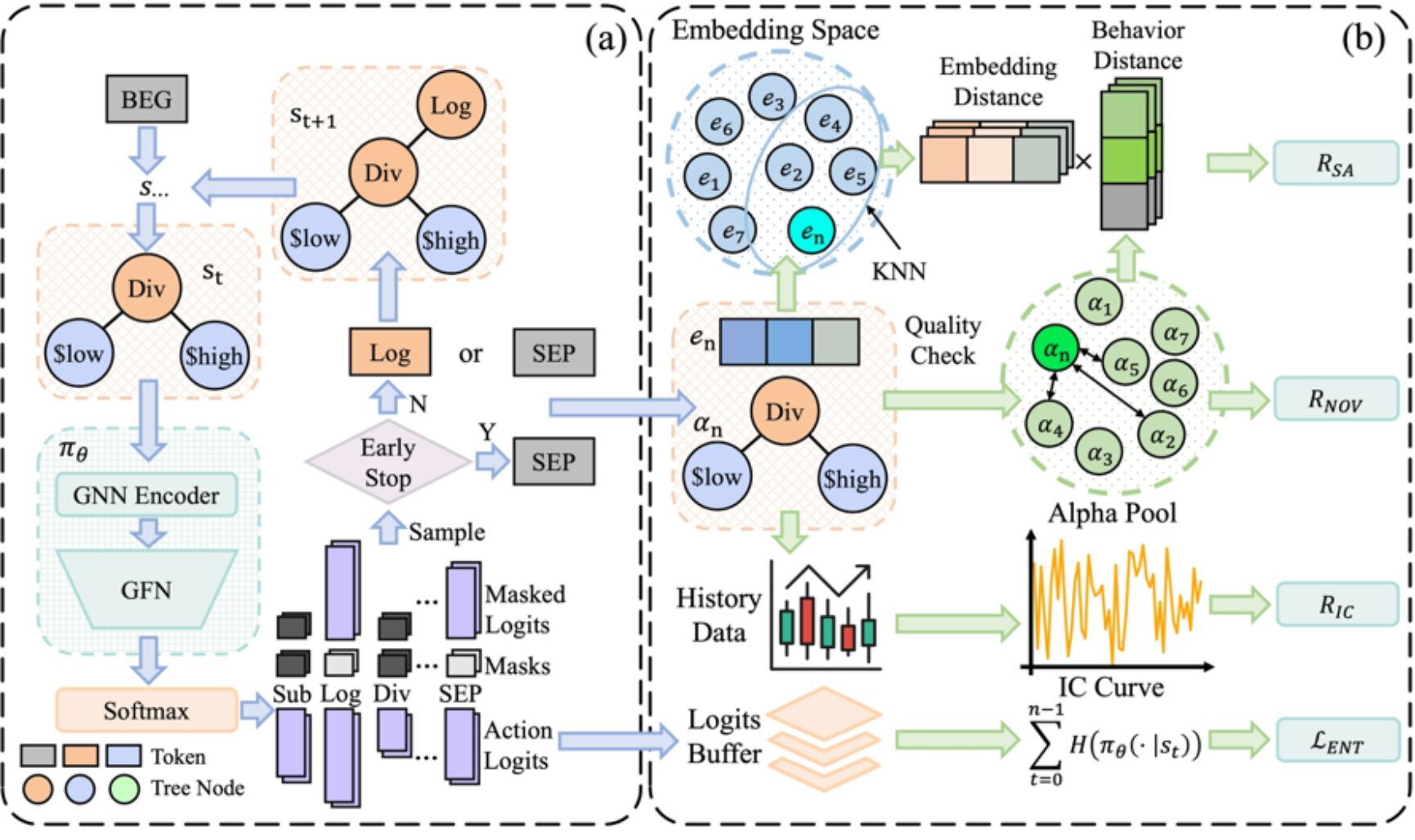
强化学习(RL)驱动的公式化alpha自动挖掘虽被视为量化金融中的重要途径,但现有框架普遍受三类相互耦合的问题制约:其一,奖励高度稀疏,往往只有完整表达式生成后才获得有效反馈,导致探索低效且训练不稳定;其二,表达式多采用顺序化表示,难以刻画决定alpha行为的结构语义;其三,最大化期望回报的标准RL目标会将策略推向单一最优模式,与实务中需要一组多样且低相关 alpha 组合的目标相矛盾。为此,本文提出AlphaSAGE,以结构感知表示、多峰分布建模与稠密奖励设计为核心,构建一种面向鲁棒探索的自动化alpha挖掘新范式,并在实验中验证其能够挖掘出更具多样性、更高新颖性且预测力更强的alpha组合。
核心创新:
1.结构感知编码器:采用基于关系图卷积网络的结构编码,将数学表达式显式建模为图结构,提升对表达式结构语义与算子关系的表征能力。
2.GFlowNet挖掘框架:引入生成流网络学习覆盖多峰解空间的采样分布,避免RL单峰收敛带来的同质化,支持生成多样、低相关的alpha候选集合。
3.稠密多维奖励机制:设计密集且多维的奖励结构,在生成过程中提供更连续的学习信号,缓解奖励稀疏并提升探索效率与稳定性,从而促进挖掘到更优质的 alpha组合。
实验效果:在不同风格、不同规模的市场中(CSI300、CSI500、CSI1000、S&P500)的多种纬度的指标下(IC、ICIR、年化收益、最大回撤等),AlphaSAGE相较于基线均取得了最优的结果。
该论文的作者包括陈滨琪(北京大学,导师为张铭教授),丁宏骏(纽约市立大学柏鲁克分校,校友),沈宁(不列颠哥伦比亚大学),郭泰安(北京大学,导师为张铭教授),黄进晟(北京大学,导师为张铭教授),刘卢琛(正仁量化,校友),张铭(北京大学,通讯作者)。
三、PRISM:融合空间与频谱线索的部分标签关系推断
论文名:PRISM: Partial-label Relational Inference with Spatial and Spectral Cues
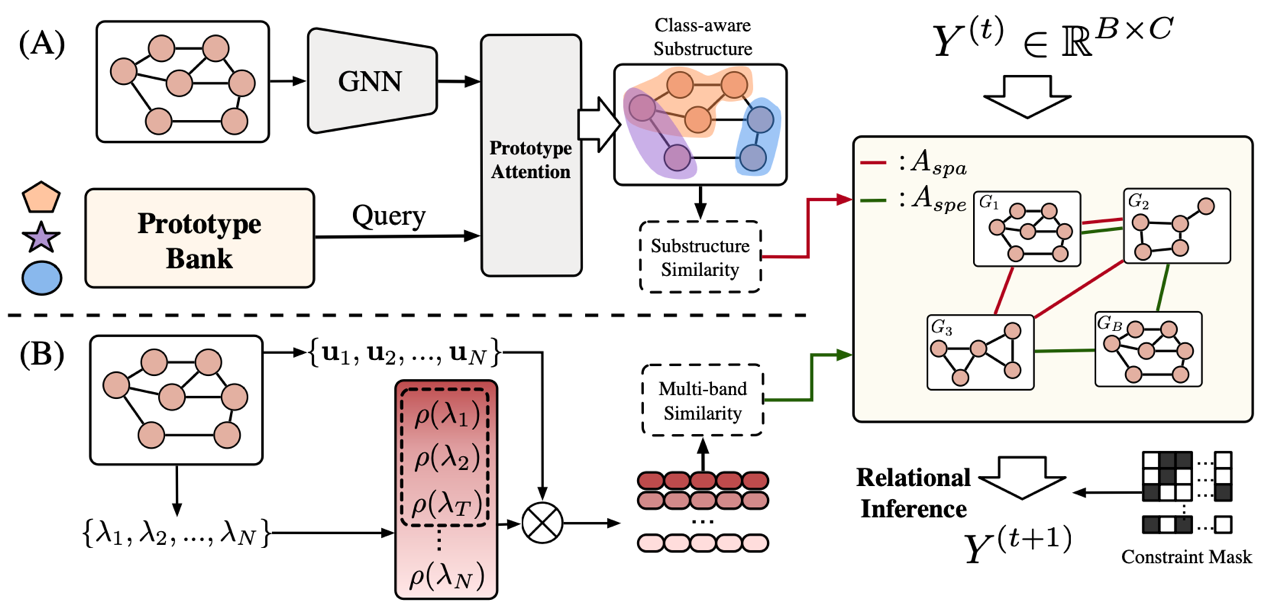
在真实世界的图学习任务中,精确标注往往代价高昂甚至不可行,模糊或带有歧义的监督成为常态。针对这一关键挑战,本文提出 PRISM:一个面向部分标签图学习的统一关系推断框架。PRISM 从结构与频谱两个互补视角出发,通过原型引导的判别性子结构对齐捕捉关键空间线索,并利用多频带谱分解与注意力机制建模全局结构语义,在候选标签约束下构建混合关系图,实现置信度感知的标签传播与改进。无需真实标签或额外辅助信号,PRISM 即可在高度噪声与强歧义监督条件下稳定学习可靠语义表示。大量不同领域的图基准实验表明,PRISM 在不同噪声水平下均显著优于现有方法,展现出卓越的鲁棒性与泛化能力,为弱监督图分类提供了一种多视角驱动的通用新范式。
该论文作者包含顾怿洋(北京大学,导师为张铭教授),吴文睿(北京大学),覃义方(北京大学,导师为张铭教授),郭泰安(北京大学,导师为张铭教授),者韬(堪萨斯大学),唐嘉如(北京大学),肖之屏(华盛顿大学,校友),张为知(伊利诺伊大学芝加哥分校),乔子越(大湾区大学),琚玮(四川大学,校友),王东杰(堪萨斯大学),罗霄(威斯康星大学麦迪逊分校,校友),俞士纶(Philip S. Yu,伊利诺伊大学芝加哥分校),张铭(北京大学,通讯作者)。
四、COLA基于层次化共形校准的不确定性感知自适应散列
论文名: COLA: Conformalized Hierarchical Calibration for Uncertainty-Aware Adaptive Hashing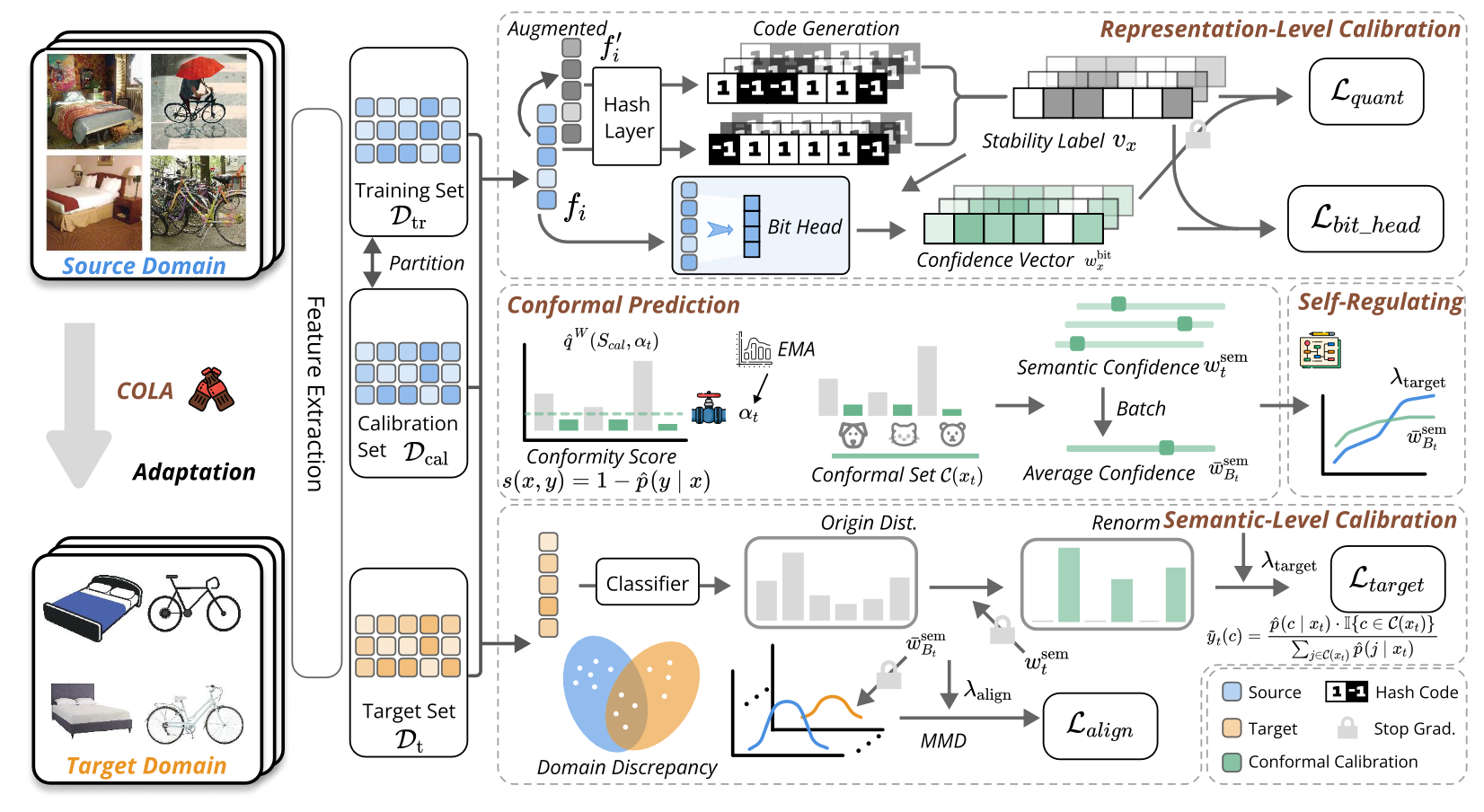
在现实的大规模检索任务中,模型常面临域偏移挑战,导致在目标域上表现出盲目自信且容易被噪声误导。本文提出了一种名为COLA的全新框架,首次将具有严谨统计保证的共形预测引入无监督域自适应散列领域。
核心创新:
语义级共形校准,摒弃了传统方法中高风险的单伪标签模式。利用共形推理生成包含多个候选类别的预测集,并通过预测集的大小精确量化样本可靠性,实现鲁棒的加权伪标签学习和自适应域对齐。
表示级比特稳定性建模,通过自监督代理任务预测每个散列比特的稳定性评分。该机制不仅能引导训练时的加权量化损失,还能在检索阶段实现不确定性感知散列距离,显著提升了散列码的抗噪声能力。
闭环自调节优化机制,我们设计了一个端到端的自调节系统,利用实时感知的语义和比特不确定性作为控制信号,动态平衡伪监督、域对齐与量化强度。该机制消除了繁琐的超参数人工调优,大幅提升了训练稳定性。
实验效果:在多个主流跨域基准数据集上,COLA均展现出卓越性能。相比现有SOTA方法,检索精度平均提升约3.3%。通过比特掩码技术,在保持严谨校准的同时,检索速度与原生散列相当,比连续向量检索快约30倍。
该论文作者包含罗钧宇(北京大学,导师为张铭教授),黄进晟(北京大学,导师为张铭教授),徐洋(北京大学),邹鲁童(北京大学),罗霄(威斯康星大学麦迪逊分校,校友),吴伯涵(北京大学,导师为张铭教授),王一帆(对外经贸,校友),琚玮(四川大学,校友),张铭(北京大学,通讯作者)
五、HINT 基于层级编码树与模态混合的跨模态散列
论文名:HINT: Hierarchical Encoding Tree with Modality Mixup for Cross-modal Hashing
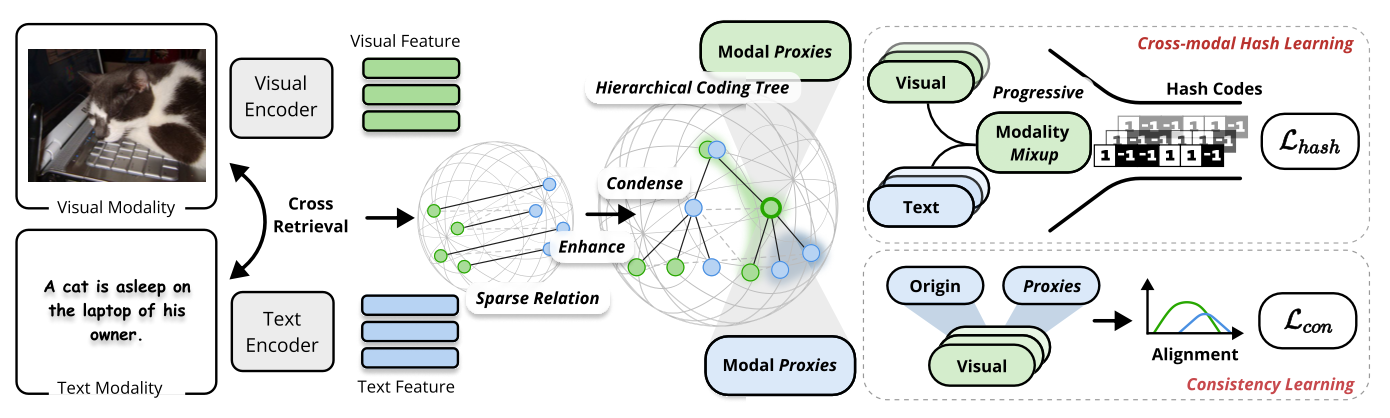
现有的无监督跨模态散列方法受限于扁平化的成对对齐,难以捕捉复杂的层级语义结构,且模态异构鸿沟难以直接跨越。为此,本文提出HINT框架,通过构建层级编码树与渐进式模态混合,实现从局部社区挖掘到全局语义对齐的突破。
核心创新:
1. 结构熵指导的层级编码树,打破扁平化学习范式,利用结构熵构建层级树,在无标签环境下精准挖掘数据的局部语义社区,捕捉细粒度语义关联。
2. 课程化模态混合机制,设计基于模态代理的渐进式混合策略。通过构建从单模态到跨模态的课程学习路径,动态消除模态间的异构鸿沟,平滑优化过程。
3. 全景语义一致性,引入基于代理的分布对齐约束,在全局视角下优化原始样本与跨模态代理的语义一致性,显著提升散列码的判别力与泛化性 。
实验效果:在多个基准上均取得SOTA性能,且在 10%噪声数据下仍保持鲁棒,兼具高效的训练与检索能力。
该论文作者包含罗钧宇(北京大学,导师为张铭教授),肖之屏(华盛顿大学,校友),周航(北卡罗来纳大学),赵禹昇(北京大学,导师为张铭教授),罗霄(威斯康星大学麦迪逊分校,校友),王鹏云(牛津大学),琚玮(四川大学,校友),Siyu Heng(纽约大学),张铭(北京大学,通讯作者)
六、CONST:大模型强化学习中的“样本彩票”无监督发现
论文名:Sample Lottery: Unsupervised Discovery of Critical Instances in RLVR of LLMs
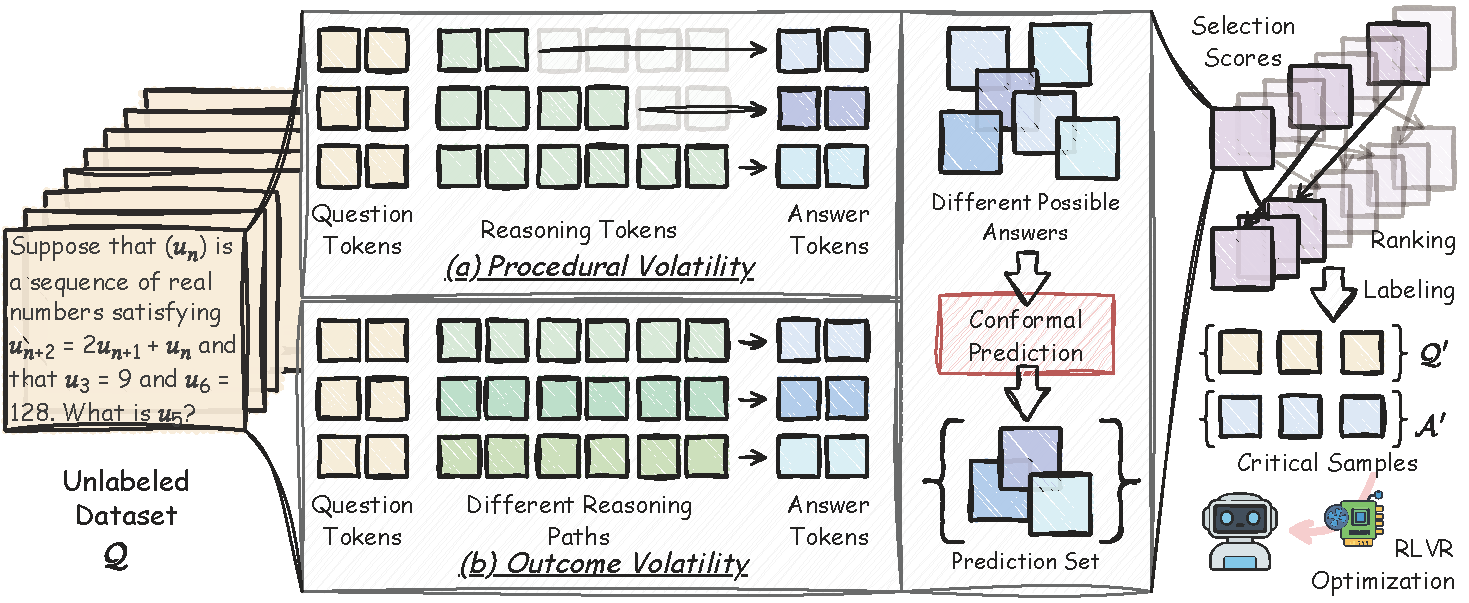
可验证奖励的强化学习RLVR 虽能显著增强大模型推理能力,但全量标注与均匀计算分配导致了高昂的资源开销。为此,本文提出“样本彩票假说”,即极少量关键子集即可匹敌全量训练效果,并据此设计了无监督框架 CONST。该框架无需真实标签,即可从原始数据中精准挖掘出这些高价值的“彩票样本”。
核心创新:
1.互补波动性评估:融合过程与结果双重波动性,通过量化推理路径截断变化与答案不一致性,构建无监督的样本价值度量。
2.保形预测选择:引入保形预测将波动性映射为预测集,直接以集合基数为判据筛选“彩票样本”,实现样本重要性的精准排序。
3.理论最优性保证:从数学上证明了在样本彩票假说下,筛选子集可逼近全量数据训练的最优策略参数,并给出了严格的误差上界。
实验效果:在多个数学推理基准数据集(如 AMC23, MATH500 等)及不同架构的大模型上,CONST 仅需不到 0.5% 的样本标注量,即可达到与全量数据训练相当的性能,并显著优于现有的主动学习基线方法。
该论文作者包含肖之屏(华盛顿大学,校友),赵禹昇(北京大学,导师为张铭教授),张岐鑫(南洋理工大学),谢佳晔(北京大学),赵万佳(斯坦福大学),张为知(伊利诺伊大学芝加哥分校),罗霄(威斯康星大学麦迪逊分校,校友),俞士纶(伊利诺伊大学芝加哥分校),张铭(北京大学,通讯作者)。